Batch Normalization#
Overview#
Batch Normalization (BatchNorm) is a technique used in training deep neural networks to improve the stability and performance of the model. By normalizing the inputs to each layer, it addresses issues like internal covariate shift, leading to several benefits:
Stabilizes Learning: Reduces internal covariate shift by normalizing inputs, making the learning process more stable.
Speeds Up Training: Models with batch normalization can converge faster and are less sensitive to the initial learning rate.
Improves Generalization: Acts as a regularizer, potentially reducing the need for other regularization techniques like dropout.
Motivation#
Batch normalization works by normalizing the output of each layer:
Compute Mean and Standard Deviation: Calculate the mean \(\mu\) and standard deviation \(\sigma\) for each feature in the mini-batch.
Normalize: Subtract the mean and divide by the standard deviation:
\[\hat{x} = \frac{x - \mu}{\sigma}\]Scale and Shift: Apply learnable parameters \(\gamma\) (scale) and \(\beta\) (shift) to the normalized output:
\[y = \gamma \hat{x} + \beta\]
Here, \(\gamma\) and \(\beta\) are parameters learned during training, allowing the network to maintain the representational power.
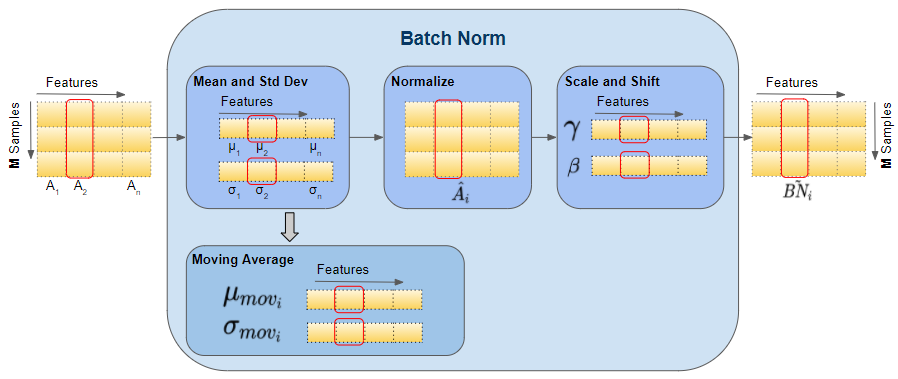
Train Time#
During training, the normalization process uses the statistics of the current mini-batch:
Calculate Batch Statistics: Compute the mean and variance for each feature in the mini-batch.
Normalize: Use these statistics to normalize the inputs of each layer.
Apply Learnable Parameters: Adjust the normalized inputs using the learnable parameters \(\gamma\) and \(\beta\).
Test Time#
During inference (test time), batch normalization uses running estimates of the mean and variance, accumulated during training:
Running Statistics: Use the running mean and running variance instead of batch statistics.
Normalize: Normalize inputs using these running statistics to ensure consistency and stability.
This ensures that the model’s performance is consistent regardless of the mini-batch size used during training.
Batch Normalization in Convolutional Neural Networks (CNNs)#
In CNNs, batch normalization is typically applied per channel rather than per feature. Each feature map (channel) is normalized independently:
Normalize Per Channel: Calculate the mean and variance for each channel across the spatial dimensions.
Apply Learnable Parameters: Adjust each channel using the channel-specific \(\gamma\) and \(\beta\) parameters.
This approach helps in maintaining the spatial structure of the input while normalizing the feature maps.
Additional Notes#
Redundant Bias: When using batch normalization, the bias term in the preceding linear or convolutional layer becomes redundant, as it can be absorbed into the \(\gamma\) and \(\beta\) parameters.
Hyperparameter \(\rho\): During training, a momentum parameter \(\rho\) is often used to update the running mean and variance.
Visual Representations#
Figures illustrating the training and test time mechanisms for batch normalization can be very helpful in understanding these processes.
# Example PyTorch implementation of Batch Normalization
import torch
import torch.nn as nn
# Define a simple model with BatchNorm
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.bn1 = nn.BatchNorm1d(256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.fc1(x)
x = self.bn1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
# Instantiate and print the model
model = SimpleModel()
print(model)
In this example, the model includes a fully connected layer followed by batch normalization. This setup helps stabilize and accelerate the training process.