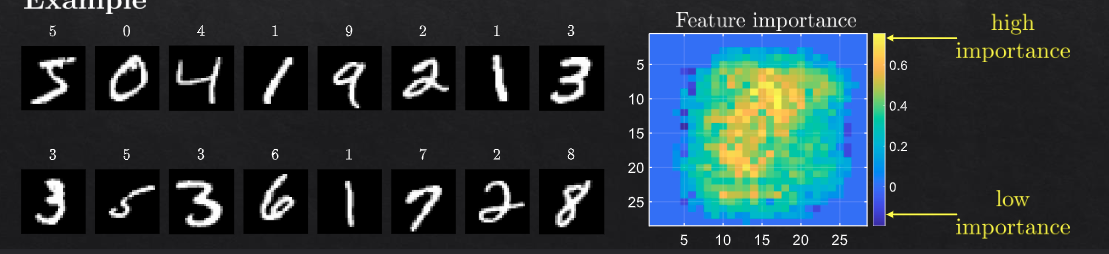
permutation importance#
General Overview: Permutation importance is a model-agnostic technique used to assess the importance of features in a machine learning model. It involves shuffling the values of each feature to measure the impact on the model’s performance. This method helps in understanding which features contribute the most to the predictive power of the model.
Key Concepts:
Model-Agnostic: Permutation importance can be applied to any machine learning model, regardless of its internal workings.
Performance Metric: A performance metric (such as accuracy for classification or mean squared error for regression) is chosen to evaluate the model.
Shuffling: Each feature’s values are shuffled one at a time, breaking the relationship between the feature and the target variable.
Impact Measurement: The decrease in the model’s performance due to shuffling indicates the importance of the feature. The greater the decrease, the more important the feature is.
Procedure:
Baseline Performance: First, calculate the baseline performance of the model using the chosen metric.
Shuffle and Predict: For each feature, shuffle its values while keeping other features unchanged, then make predictions with the model.
Compute Drop in Performance: Calculate the performance with the shuffled feature and determine the drop from the baseline performance.
Rank Features: Rank the features based on the drop in performance, with larger drops indicating higher importance.
Applications:
Feature Selection: Identifying and removing features that do not significantly impact the model’s performance.
Interpretability: Enhancing the interpretability of complex models by highlighting the most influential features.
Model Debugging: Diagnosing issues with model predictions by examining the impact of different features.
Advantages:
Model Independence: Works with any machine learning model.
Simplicity: Easy to implement and understand.
Interpretability: Provides clear insights into feature importance.
Disadvantages:
Computational Cost: Can be computationally expensive, especially for large datasets or complex models, as it requires multiple evaluations of the model.
Correlation Sensitivity: May not correctly identify the importance of correlated features, as shuffling one correlated feature might still leave enough information in the other correlated feature(s).
Noisy Estimates: Can produce noisy importance scores if the model or data is highly variable.
In summary, permutation importance is a straightforward and versatile method to determine feature importance, providing valuable insights into which features most influence a model’s predictions. Despite its computational demands and sensitivity to feature correlations, it remains a popular choice for feature analysis in machine learning.
notes#
permutation importance is a technique to measure the importance of a feature by shuffling the values of the feature and measuring the impact on the model’s performance.
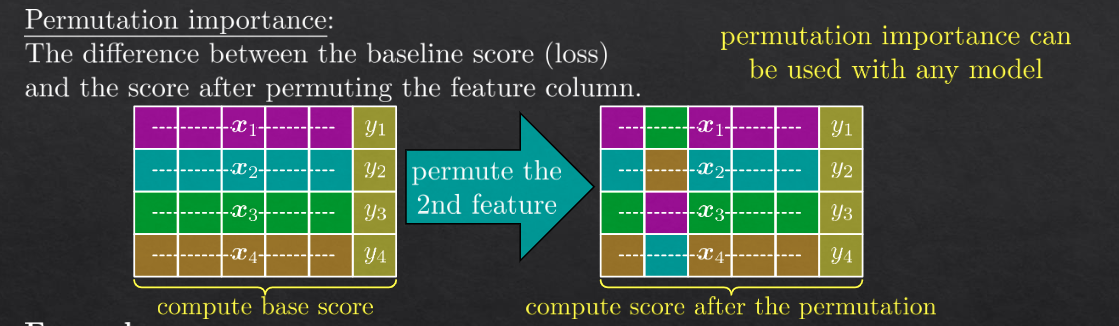
example#