precision and recall#
Precision and Recall#
General Overview#
Precision and recall are two fundamental metrics used in the evaluation of classification models, particularly in contexts where the data is imbalanced or the cost of different types of errors varies. These metrics help us understand the performance of a classifier beyond simple accuracy.
Precision#
Precision measures the accuracy of the positive predictions made by the model. It is defined as the ratio of true positive predictions to the total number of positive predictions (both true positives and false positives).
where:
\( TP\) (True Positives) are the correctly predicted positive instances.
\( FP\) (False Positives) are the incorrectly predicted positive instances.
High precision indicates that the model produces more relevant results and fewer irrelevant ones.
Recall#
Recall, also known as sensitivity or true positive rate, measures the ability of the model to identify all relevant instances. It is defined as the ratio of true positive predictions to the total number of actual positives (both true positives and false negatives).
where:
\( FN\) (False Negatives) are the instances where the model incorrectly predicts the negative class.
High recall indicates that the model captures most of the relevant instances, even if it also includes some irrelevant ones.
Trade-off between Precision and Recall#
In practice, there is often a trade-off between precision and recall. Increasing precision usually decreases recall and vice versa. This is because making a model more conservative in its positive predictions (to increase precision) can result in more false negatives (decreasing recall). Conversely, making a model more liberal in its positive predictions (to increase recall) can result in more false positives (decreasing precision).
To manage this trade-off, one can use the F1 score, which is the harmonic mean of precision and recall:
The F1 score provides a single metric that balances the trade-off between precision and recall.
Real-World Example#
Consider a spam email classifier:
True Positive (TP): The email is spam, and the classifier correctly identifies it as spam.
False Positive (FP): The email is not spam, but the classifier incorrectly identifies it as spam.
False Negative (FN): The email is spam, but the classifier incorrectly identifies it as not spam.
High Precision: Few legitimate emails are marked as spam. Users are less likely to miss important emails, but some spam might still get through.
High Recall: Most spam emails are caught, but more legitimate emails might also be marked as spam.
For example, if a spam classifier has 90% precision, it means that 90% of the emails flagged as spam are indeed spam. If it has 80% recall, it means that 80% of the actual spam emails are correctly identified as spam by the classifier.
Choosing between precision and recall depends on the context and the cost of false positives and false negatives. In a medical diagnosis scenario, for example, high recall is crucial to ensure that all possible cases of a disease are identified, even if it means more false positives (and thus more follow-up tests).
Trade-off Between Precision and Recall#
There is often a trade-off between precision and recall. Improving precision typically reduces recall and vice versa. This is because increasing precision usually involves being more selective in predicting positives, which can lead to missing some actual positives (thus lowering recall). Conversely, increasing recall often involves casting a wider net to capture more positives, which can include more false positives (thus lowering precision).
F1 Score#
To balance precision and recall, the F1 score is used, which is the harmonic mean of precision and recall. The F1 score is a single metric that combines both precision and recall, providing a balanced measure when the two metrics are in tension.
Example#
Suppose we have a binary classification problem with the following confusion matrix:
Predicted Positive |
Predicted Negative |
|
|---|---|---|
Actual Positive |
TP = 70 |
FN = 10 |
Actual Negative |
FP = 20 |
TN = 100 |
Precision: \( \frac{TP}{TP + FP} = \frac{70}{70 + 20} = 0.78 \)
Recall: \( \frac{TP}{TP + FN} = \frac{70}{70 + 10} = 0.88 \)
F1 Score: \( 2 \cdot \frac{0.78 \cdot 0.88}{0.78 + 0.88} = 0.83 \)
In this example, the classifier has reasonably good precision and recall, with a balanced F1 score.
Understanding and properly using precision and recall is crucial in machine learning, especially when dealing with imbalanced datasets or when the cost of false positives and false negatives differs significantly.
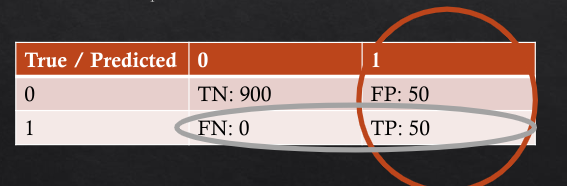
how to calc from confusion matrix:#