
Naive Bayes Classifier#
Sentiment Analysis#
Notebook by:
Royi Avital RoyiAvital@fixelalgorithms.com
Revision History#
Version |
Date |
User |
Content / Changes |
|---|---|---|---|
1.0.000 |
22/03/2024 |
Royi Avital |
First version |
![]()
# Import Packages
# General Tools
import numpy as np
import scipy as sp
import pandas as pd
# Machine Learning
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
from sklearn.metrics import precision_recall_fscore_support
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
import nltk
from nltk.corpus import stopwords, names
from nltk.stem import WordNetLemmatizer
# Image Processing
# Machine Learning
# Miscellaneous
import math
import os
from platform import python_version
import random
import timeit
# Typing
from typing import Callable, Dict, List, Optional, Set, Tuple, Union
# Visualization
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
# Jupyter
from IPython import get_ipython
from IPython.display import Image
from IPython.display import display
from ipywidgets import Dropdown, FloatSlider, interact, IntSlider, Layout, SelectionSlider
from ipywidgets import interact
Notations#
(?) Question to answer interactively.
(!) Simple task to add code for the notebook.
(@) Optional / Extra self practice.
(#) Note / Useful resource / Food for thought.
Code Notations:
someVar = 2; #<! Notation for a variable
vVector = np.random.rand(4) #<! Notation for 1D array
mMatrix = np.random.rand(4, 3) #<! Notation for 2D array
tTensor = np.random.rand(4, 3, 2, 3) #<! Notation for nD array (Tensor)
tuTuple = (1, 2, 3) #<! Notation for a tuple
lList = [1, 2, 3] #<! Notation for a list
dDict = {1: 3, 2: 2, 3: 1} #<! Notation for a dictionary
oObj = MyClass() #<! Notation for an object
dfData = pd.DataFrame() #<! Notation for a data frame
dsData = pd.Series() #<! Notation for a series
hObj = plt.Axes() #<! Notation for an object / handler / function handler
Code Exercise#
Single line fill
vallToFill = ???
Multi Line to Fill (At least one)
# You need to start writing
????
Section to Fill
#===========================Fill This===========================#
# 1. Explanation about what to do.
# !! Remarks to follow / take under consideration.
mX = ???
???
#===============================================================#
# Configuration
# %matplotlib inline
seedNum = 512
np.random.seed(seedNum)
random.seed(seedNum)
# Matplotlib default color palette
lMatPltLibclr = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf']
# sns.set_theme() #>! Apply SeaBorn theme
runInGoogleColab = 'google.colab' in str(get_ipython())
nltk.download('stopwords')
nltk.download('names')
[nltk_data] Downloading package stopwords to /home/vlad/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package names to /home/vlad/nltk_data...
[nltk_data] Package names is already up-to-date!
True
# Constants
DATA_FILE_ID = r'12G6oUKCWzQnkDbv3TIcL9120YBdCwAmW'
L_DATA_FILE_NAME = ['IMDBReviewsText.txt', 'IMDBReviewsLabels.txt']
D_CATEGORY = {'positive': 1, 'negative': 0}
# Courses Packages
import sys
sys.path.append('../')
sys.path.append('../../')
sys.path.append('../../../')
from utils.DataManipulation import DownloadGDriveZip
from utils.DataVisualization import PlotConfusionMatrix, PlotLabelsHistogram
# General Auxiliary Functions
Naive Bayes Classifier#
The Naive Bayes Classifier is built on the assumption conditional independence between every pair of features given the value of the class variable.
Assume probabilistic model for the class given a set of features \(\boldsymbol{x}\):
Using the naive conditional independence assumption yields:
Given \(P \left( {x}_{1}, \dots, {x}_{d} \right)\) is a constant, one can optimize:
The classifier model is set by the distribution set to the \(i\) -th feature given the class: \(P \left( {x}_{i} \mid y \right)\).
(#) In lectures, for continuous features, a more general case is described where the features are Jointly Gaussian.
(#) The general case, where the joint distribution of the features (Which can be dependent) is unknown is usually modeled by a Bayesian Net.
One way to implement such net is by a Neural Network Net. See Neural Networks vs. Bayesian Networks and Ehud Reiter’s Blog - Bayesian vs Neural Networks.
Sentiment Analysis#
In this case highly polar reviews of movies will be analyzed for Sentiment Analysis.
The categories will be negative or positive reviews.
The RAW data is a review text.
The process of the classification will be:
Download and Load the Data
The data will be downloaded and parsed into 2 lists: Reviews, Labels.Pre Process the Data
The text data will be cleaned, the labels will be transformed into numeric values.Feature Extraction
The text will be transformed into histogram like of the words in the review.Classification
The classification will be done using Multinomial Naive Bayes model.
(#) Multinomial Distribution is a generalization of the Binomial Distribution. It suits the case of counting the number of occurrence of the words.
(#) A math deep introduction is given in Michael Collins - The Naive Bayes Model, Maximum Likelihood Estimation and the EM Algorithm.
# Parameters
# Data
numSamplesRatio = 0.1
# Features Engineering
# Minimum Frequency of words
minDf = 1
# Maximum number of features (Histogram support)
numFeaturesMax = 500_000
minRatio = 2.5
maxRatio = 5 #<! No Effect (Visualization)
# Model
α = 1
Generate / Load Data#
Loading Andrew Maas’ Large Movie Review Dataset data set.
The original data was processed into 25,000 labeled reviews (See Rockikz (x4nth055) - Sentiment Analysis Naive Bayes).
# Download Data
# Download the data from Google Drive
DownloadGDriveZip(fileId = DATA_FILE_ID, lFileCont = L_DATA_FILE_NAME)
Downloading...
From: https://drive.google.com/uc?id=12G6oUKCWzQnkDbv3TIcL9120YBdCwAmW
To: /data/solai/2024/03_ml/03_Statistical/mapClassifier/IMDBReviews.zip
100%|██████████| 11.4M/11.4M [00:01<00:00, 9.61MB/s]
# Load Data
# Read reviews - Python Context
with open(L_DATA_FILE_NAME[0]) as hFile:
lReview = hFile.readlines() #<! Each review is a line
# Read labels - Python Context
with open(L_DATA_FILE_NAME[1]) as hFile:
lLabels = hFile.readlines() #<! Each review is a line
print(f'Loaded {len(lReview)} reviews')
print(f'Loaded {len(lLabels)} labels')
Loaded 25000 reviews
Loaded 25000 labels
# Pre Processing
# 1. Remove leading and trailing spaces from text.
# 2. Convert the labels: 'negative' -> 0, 'positive' -> 1 (Numpy Array).
lReview = [reviewTxt.strip() for reviewTxt in lReview] #<! Remove leading and trailing whitespaces
vY = np.array([D_CATEGORY[labelTxt.strip()] for labelTxt in lLabels]) #<! 'negative' -> 0, 'positive' -> 1
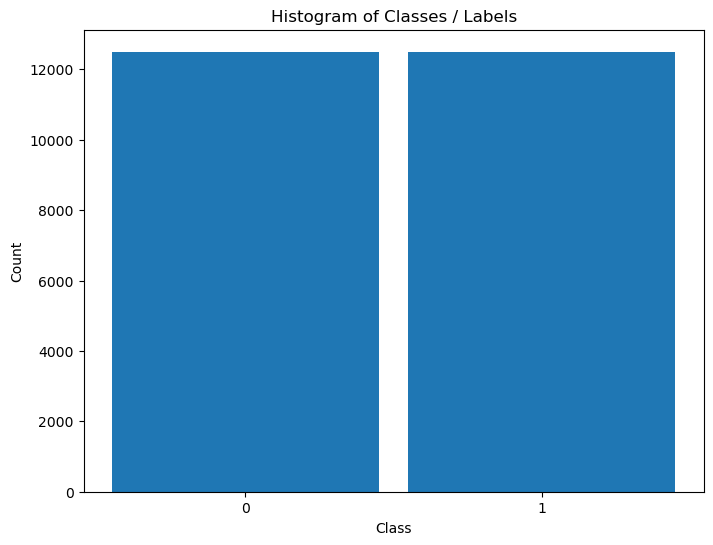
# Distribution of Labels
hA = PlotLabelsHistogram(vY)
plt.show()
Train / Test Split#
Since the feature engineering will be mostly about counting and the distribution of the words, the split is done before the feature engineering.
This is done to prevent the train data pollution / contamination (Also known as Data Leakage in Machine Learning).
numClass = len(np.unique(vY))
lReviewTrain, lReviewTest, vYTrain, vYTest = train_test_split(lReview, vY, test_size = numSamplesRatio, shuffle = True, stratify = vY)
Feature Engineering#
For simple based text tasks, most used features are based on the histogram of the words per object.
In general, the whole corpus of words in the data is described by a distribution.
(#) The most simple
In this case we’ll use SciKit Learn CountVectorizer which learns the corpus of words.
Then, in its transformation phase, build the histogram per object.
# Build the Histogram Feature Vector
# List of words to avoid counting
lNames = list(names.words())
lNames = [name.lower() for name in lNames]
lStopWords = list(stopwords.words())
lStopWords = [word.lower() for word in lStopWords]
lIgnoreWords = list(ENGLISH_STOP_WORDS) + lNames + lStopWords
# The Count Object
oCntVec = CountVectorizer(strip_accents = 'ascii', stop_words = lIgnoreWords, min_df = minDf, max_features = numFeaturesMax)
mXTrain = oCntVec.fit_transform(lReviewTrain) #<! Fit & Transform
/data/solai/venvMamabaFixel/lib/python3.11/site-packages/sklearn/feature_extraction/text.py:408: UserWarning: Your stop_words may be inconsistent with your preprocessing. Tokenizing the stop words generated tokens ['acaba', 'acesti', 'aci', 'aiba', 'aixi', 'aixo', 'aldiz', 'altal', 'altalaban', 'altms', 'ambdos', 'amig', 'aqui', 'arasnda', 'arrol', 'artq', 'aslnda', 'astia', 'ate', 'aveti', 'avra', 'avro', 'azert', 'aztan', 'azutan', 'bade', 'bae', 'baiknya', 'baizik', 'bar', 'baz', 'belul', 'berkali', 'bes', 'bilr', 'birkac', 'birsey', 'bizlr', 'blk', 'bos', 'brzcas', 'brzkone', 'bukatzeko', 'bunlarn', 'butun', 'bzi', 'bzn', 'caci', 'cadascu', 'carei', 'caror', 'carui', 'catva', 'cem', 'cemer', 'cemerkoli', 'cemu', 'cemur', 'cemurkoli', 'ceprav', 'ceravno', 'cesa', 'cesarkoli', 'cetrta', 'cetrte', 'cetrtega', 'cetrtem', 'cetrtemu', 'cetrti', 'cetrtih', 'cetrtim', 'cetrtima', 'cetrtimi', 'cetrto', 'cetudi', 'cez', 'cezenj', 'ceznje', 'cigar', 'cigav', 'cigava', 'cigave', 'cigavega', 'cigavem', 'cigavemu', 'cigavi', 'cigavih', 'cigavim', 'cigavima', 'cigavimi', 'cigavo', 'cim', 'cimer', 'cimerkoli', 'citva', 'cok', 'cox', 'cunki', 'cunku', 'data', 'despres', 'dk', 'dn', 'dord', 'doua', 'dovolis', 'dqiq', 'drugacen', 'drugacna', 'drugacne', 'drugacnega', 'drugacnem', 'drugacnemu', 'drugacni', 'drugacnih', 'drugacnim', 'drugacnima', 'drugacnimi', 'drugacno', 'duz', 'dvainsestdeset', 'dvainsestdesetih', 'dvainsestdesetim', 'dvainsestdesetimi', 'edn', 'edota', 'eger', 'egesz', 'egyeb', 'eivat', 'eleg', 'elo', 'eloszor', 'elott', 'elso', 'eppen', 'eramos', 'ereu', 'essent', 'estabamos', 'estais', 'estao', 'estara', 'estaran', 'estaras', 'estare', 'estareis', 'estaria', 'estariais', 'estariamos', 'estarian', 'estarias', 'estavamos', 'estavem', 'estaveu', 'esteis', 'esten', 'esti', 'estiveramos', 'estivessemos', 'estuvieramos', 'estuviesemos', 'etaient', 'etais', 'etait', 'etant', 'etante', 'etantes', 'etants', 'ete', 'etee', 'etees', 'etes', 'etiez', 'etions', 'etm', 'etmk', 'eumes', 'eutes', 'eze', 'ezert', 'ezpabere', 'ezpada', 'ezperen', 'faro', 'fele', 'fiti', 'foramos', 'fossemos', 'fr', 'fueramos', 'fuesemos', 'fumes', 'fur', 'futes', 'gainera', 'gainerontzean', 'gairebe', 'gor', 'gr', 'guztiz', 'habeis', 'habia', 'habiais', 'habiamos', 'habian', 'habias', 'habra', 'habran', 'habras', 'habre', 'habreis', 'habria', 'habriais', 'habriamos', 'habrian', 'habrias', 'hainbestez', 'haneen', 'hanella', 'hanelle', 'hanelta', 'hanen', 'hanessa', 'hanesta', 'hanet', 'hanta', 'hao', 'haqqnda', 'hayais', 'hec', 'heidan', 'heidat', 'heilla', 'heilta', 'heissa', 'heista', 'heita', 'hic', 'hja', 'hmin', 'hmis', 'hoce', 'hocejo', 'hocem', 'hocemo', 'hoces', 'hoceta', 'hocete', 'hoceva', 'horra', 'houveramos', 'houverao', 'houveriamos', 'houvessemos', 'hr', 'hubieramos', 'hubiesemos', 'icin', 'igy', 'ild', 'inclos', 'ismet', 'istifad', 'jol', 'kakrsen', 'kakrsenkoli', 'kakrsna', 'kakrsnakoli', 'kakrsne', 'kakrsnega', 'kakrsnegakoli', 'kakrsnekoli', 'kakrsnem', 'kakrsnemkoli', 'kakrsnemu', 'kakrsnemukoli', 'kakrsni', 'kakrsnih', 'kakrsnihkoli', 'kakrsnikoli', 'kakrsnim', 'kakrsnima', 'kakrsnimakoli', 'kakrsnimi', 'kakrsnimikoli', 'kakrsnimkoli', 'kakrsno', 'kakrsnokoli', 'kaksen', 'kaksna', 'kaksne', 'kaksnega', 'kaksnem', 'kaksnemu', 'kaksni', 'kaksnih', 'kaksnim', 'kaksnima', 'kaksnimi', 'kaksno', 'keilla', 'keilta', 'keina', 'keissa', 'keista', 'keita', 'kenella', 'kenelta', 'kenena', 'kenessa', 'kenesta', 'keressunk', 'keresztul', 'keta', 'ketka', 'kivul', 'koliksen', 'koliksna', 'koliksne', 'koliksnega', 'koliksnem', 'koliksnemu', 'koliksni', 'koliksnih', 'koliksnim', 'koliksnima', 'koliksnimi', 'koliksno', 'konnen', 'konnte', 'kozott', 'kozul', 'kurangnya', 'langa', 'lbtt', 'legalabb', 'linga', 'lli', 'luc', 'magat', 'maras', 'marsicem', 'marsicemu', 'marsicesa', 'marsicim', 'marvec', 'masik', 'mata', 'meidan', 'meidat', 'meilla', 'meilta', 'meissa', 'meista', 'meita', 'meme', 'mhz', 'mias', 'miert', 'miine', 'milla', 'milta', 'minka', 'mios', 'mirsey', 'missa', 'mista', 'mita', 'mitka', 'mn', 'moci', 'moras', 'mores', 'nagon', 'nagot', 'nagra', 'naiden', 'naihin', 'naiksi', 'nailla', 'naille', 'nailta', 'naina', 'naissa', 'naista', 'naita', 'najbrz', 'namrec', 'nao', 'nar', 'nasa', 'nasega', 'nasem', 'nasemu', 'nasi', 'nasih', 'nasim', 'nasima', 'nasimi', 'nasl', 'naso', 'necem', 'necemu', 'necesa', 'necim', 'neha', 'nehany', 'nekaksen', 'nekaksna', 'nekaksne', 'nekaksnega', 'nekaksnem', 'nekaksnemu', 'nekaksni', 'nekaksnih', 'nekaksnim', 'nekaksnima', 'nekaksnimi', 'nekaksno', 'nelkul', 'nhayt', 'nic', 'nicemer', 'nicemur', 'nicesar', 'nicimer', 'nicin', 'nihce', 'niilla', 'niilta', 'niina', 'niissa', 'niista', 'niita', 'nikakrsen', 'nikakrsna', 'nikakrsne', 'nikakrsnega', 'nikakrsnem', 'nikakrsnemu', 'nikakrsni', 'nikakrsnih', 'nikakrsnim', 'nikakrsnima', 'nikakrsnimi', 'nikakrsno', 'niy', 'noastra', 'noce', 'nocejo', 'nocem', 'nocemo', 'noces', 'noceta', 'nocete', 'noceva', 'nomes', 'ogsa', 'oket', 'olah', 'oldugu', 'olmad', 'olmusdur', 'onlarn', 'ordea', 'oricand', 'oricat', 'oricind', 'oricit', 'oseminstirideset', 'oseminstiridesetih', 'oseminstiridesetim', 'oseminstiridesetimi', 'ossze', 'osterantzean', 'oz', 'ozu', 'pac', 'pana', 'perche', 'perque', 'petinstirideset', 'petinstirideseta', 'petinstiridesete', 'petinstiridesetega', 'petinstiridesetem', 'petinstiridesetemu', 'petinstirideseti', 'petinstiridesetih', 'petinstiridesetim', 'petinstiridesetima', 'petinstiridesetimi', 'petinstirideseto', 'piu', 'printr', 'putin', 'putina', 'qars', 'qdr', 'qrx', 'ra', 'sadan', 'sadana', 'sadant', 'sadc', 'sajat', 'saniy', 'sann', 'sao', 'saro', 'seais', 'sedeminsestdeset', 'sedeminsestdesetih', 'sedeminsestdesetim', 'sedeminsestdesetimi', 'sekurang', 'sele', 'seran', 'serao', 'sere', 'sereis', 'seriais', 'seriamos', 'serian', 'serias', 'sest', 'sesta', 'sestdeset', 'sestdeseta', 'sestdesete', 'sestdesetega', 'sestdesetem', 'sestdesetemu', 'sestdeseti', 'sestdesetih', 'sestdesetim', 'sestdesetima', 'sestdesetimi', 'sestdeseto', 'seste', 'sestega', 'sestem', 'sestemu', 'sesti', 'sestih', 'sestim', 'sestima', 'sestimi', 'sestindvajset', 'sestindvajsetih', 'sestindvajsetim', 'sestindvajsetimi', 'sestintrideset', 'sestintridesetih', 'sestintridesetim', 'sestintridesetimi', 'sestnajst', 'sestnajsta', 'sestnajste', 'sestnajstega', 'sestnajstem', 'sestnajstemu', 'sestnajsti', 'sestnajstih', 'sestnajstim', 'sestnajstima', 'sestnajstimi', 'sestnajsto', 'sesto', 'seststo', 'seststotih', 'seststotim', 'seststotimi', 'setidak', 'sey', 'shv', 'siina', 'siita', 'silla', 'silta', 'sita', 'sizlr', 'sjalv', 'sjl', 'skkiz', 'sksn', 'slind', 'smes', 'sn', 'snin', 'sprico', 'stara', 'staro', 'stiri', 'stirideset', 'stirideseta', 'stiridesete', 'stiridesetega', 'stiridesetem', 'stiridesetemu', 'stirideseti', 'stiridesetih', 'stiridesetim', 'stiridesetima', 'stiridesetimi', 'stirideseto', 'stirih', 'stiriindvajset', 'stiriindvajseta', 'stiriindvajsete', 'stiriindvajsetega', 'stiriindvajsetem', 'stiriindvajsetemu', 'stiriindvajseti', 'stiriindvajsetih', 'stiriindvajsetim', 'stiriindvajsetima', 'stiriindvajsetimi', 'stiriindvajseto', 'stirim', 'stirimi', 'stirinajst', 'stirinajsta', 'stirinajste', 'stirinajstega', 'stirinajstem', 'stirinajstemu', 'stirinajsti', 'stirinajstih', 'stirinajstim', 'stirinajstima', 'stirinajstimi', 'stirinajsto', 'stiristo', 'stiristotih', 'stiristotim', 'stiristotimi', 'stirje', 'sunteti', 'szamara', 'tahan', 'taksen', 'taksi', 'taksna', 'taksne', 'taksnega', 'taksnem', 'taksnemu', 'taksni', 'taksnih', 'taksnim', 'taksnima', 'taksnimi', 'taksno', 'talan', 'talla', 'talle', 'talta', 'tama', 'taman', 'tambe', 'tambem', 'tambien', 'tassa', 'tasta', 'tata', 'tau', 'tehat', 'teidan', 'teidat', 'teilla', 'teilta', 'teissa', 'teista', 'teita', 'temvec', 'tendra', 'tendran', 'tendras', 'tendre', 'tendreis', 'tendria', 'tendriais', 'tendriamos', 'tendrian', 'tendrias', 'teneis', 'tengais', 'tenia', 'teniais', 'teniamos', 'tenian', 'tenias', 'terao', 'teriamos', 'tidaknya', 'tie', 'tinhamos', 'tisoc', 'tisoca', 'tisoce', 'tisocega', 'tisocem', 'tisocemu', 'tisocer', 'tisocera', 'tisocere', 'tisocerega', 'tisocerem', 'tisoceremu', 'tisoceri', 'tisocerih', 'tisocerim', 'tisocerima', 'tisocerimi', 'tisocero', 'tisoci', 'tisocih', 'tisocim', 'tisocima', 'tisocimi', 'tisoco', 'tiveramos', 'tivessemos', 'tobb', 'toliksen', 'toliksna', 'toliksne', 'toliksnega', 'toliksnem', 'toliksnemu', 'toliksni', 'toliksnih', 'toliksnim', 'toliksnima', 'toliksnimi', 'toliksno', 'tovabb', 'tovabba', 'triinsestdeset', 'triinsestdesetih', 'triinsestdesetim', 'triinsestdesetimi', 'tssuf', 'tuota', 'tuvieramos', 'tuviesemos', 'uber', 'uc', 'ucun', 'ugy', 'uj', 'ujabb', 'ujra', 'ultim', 'utana', 'utolso', 'valo', 'varfor', 'vasa', 'vasega', 'vasem', 'vasemu', 'vasi', 'vasih', 'vasim', 'vasima', 'vasimi', 'vaso', 'vnovic', 'voastra', 'voce', 'voces', 'voua', 'vprico', 'vre', 'vret', 'vrt', 'vsakrsen', 'vsakrsna', 'vsakrsne', 'vsakrsnega', 'vsakrsnem', 'vsakrsnemu', 'vsakrsni', 'vsakrsnih', 'vsakrsnim', 'vsakrsnima', 'vsakrsnimi', 'vsakrsno', 'vsec', 'vstric', 'vzdolz', 'wahrend', 'wurde', 'wurden', 'xanm', 'yalnz', 'yaxs', 'yen', 'yetmis', 'yni', 'yuz', 'zelel', 'zelela', 'zelele', 'zeleli', 'zelelo', 'zelen', 'zelena', 'zelene', 'zeleni', 'zeleno', 'zeleti', 'zeli', 'zelijo', 'zelim', 'zelimo', 'zelis', 'zelita', 'zelite', 'zeliva', 'zmoci', 'zmores', 'zsa'] not in stop_words.
warnings.warn(
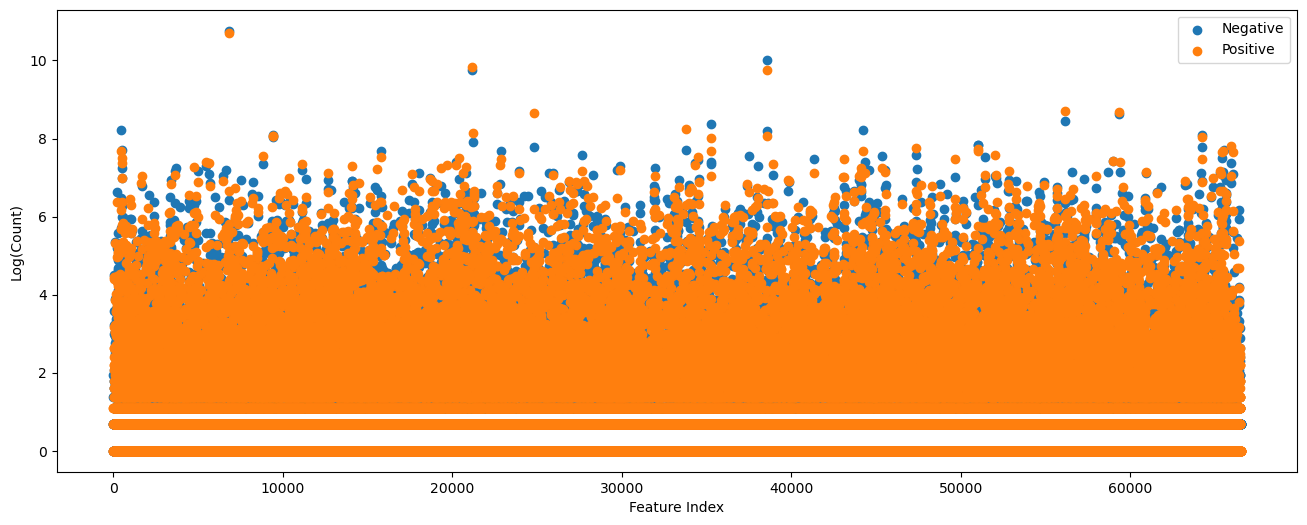
The features matrix is large and sparse.
The next move is to select important features.
The concept, per feature, if it has some tendency to either class.
It makes sense since the assumption is each feature is independent of other given class.
# The Class Ratio per Feature
numFeatures = len(oCntVec.vocabulary_)
lFeatNames = list(oCntVec.get_feature_names_out())
vClassRatio = np.zeros(numFeatures)
# Number of occurrence per class
vSumNeg = mXTrain.T @ (vYTrain == D_CATEGORY['negative'])
vSumPos = mXTrain.T @ (vYTrain == D_CATEGORY['positive'])
hF, hA = plt.subplots(figsize = (16, 6))
hA.scatter(range(numFeatures), np.log1p(vSumNeg), color = lMatPltLibclr[0], label = 'Negative')
hA.scatter(range(numFeatures), np.log1p(vSumPos), color = lMatPltLibclr[1], label = 'Positive')
hA.set_xlabel('Feature Index')
hA.set_ylabel('Log(Count)')
hA.legend();
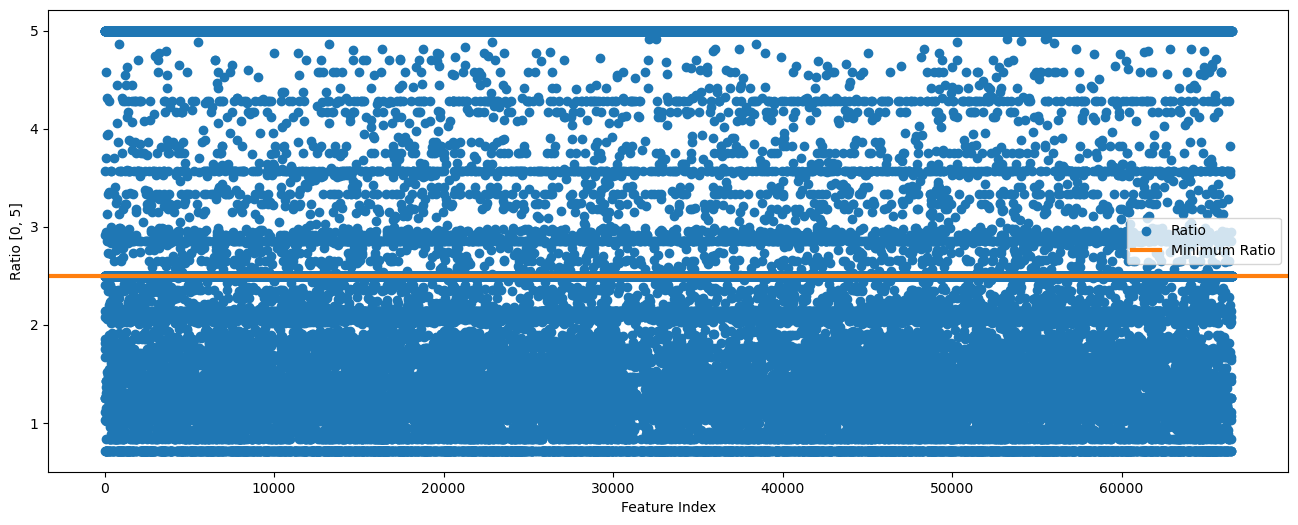
# Ratio per Feature
# The ratio between the counts.
# To make it symmetric, we'll take the maximum of both sides.
vClsRatio = np.nanmax(np.column_stack((vSumNeg / (vSumPos + (1 / minRatio)), vSumPos / (vSumNeg + (1 / minRatio)))), axis = 1)
# Limit the ratio to [0, 2]
vClsRatio = np.clip(vClsRatio, a_min = 0, a_max = maxRatio)
# Plot the Ratio
hF, hA = plt.subplots(figsize = (16, 6))
hA.scatter(range(numFeatures), vClsRatio, color = lMatPltLibclr[0], label = 'Ratio')
hA.axhline(y = minRatio, lw = 3, color = lMatPltLibclr[1], label = 'Minimum Ratio')
hA.set_xlabel('Feature Index')
hA.set_ylabel(f'Ratio [0, {maxRatio}]')
hA.legend();
Now, we build the words dictionary based on the selected words only.
# Words Dictionary
lDicWord = list(oCntVec.get_feature_names_out()[vClsRatio >= minRatio])
lDicWord
['aaa',
'aaaaaaah',
'aaaaah',
'aaaaatch',
'aaaand',
'aaaarrgh',
'aaah',
'aaaugh',
'aachen',
'aada',
'aadha',
'aag',
'aage',
'aaghh',
'aah',
'aahhh',
'aaip',
'aaja',
'aaker',
'aakrosh',
'aaliyah',
'aames',
'aankh',
'aapke',
'aapkey',
'aardman',
'aardvarks',
'aargh',
'aarrrgh',
'aatish',
'aauugghh',
'aavjo',
'aaww',
'abadi',
'abahy',
'abanazer',
'abanks',
'abas',
'abashed',
'abashidze',
'abating',
'abattoirs',
'abba',
'abbad',
'abbots',
'abbu',
'abcd',
'abdic',
'abdicates',
'abdicating',
'abdomen',
'abdominal',
'abdu',
'abductee',
'abductions',
'abductors',
'abercrombie',
'abernathy',
'aberystwyth',
'abets',
'abetted',
'abetting',
'abeyance',
'abgail',
'abhay',
'abhays',
'abhijeet',
'abhimaan',
'abhisheh',
'abhishek',
'abhorrence',
'abhorrent',
'abhors',
'abi',
'abides',
'abigil',
'abilityof',
'abishai',
'abishek',
'abject',
'abjectly',
'abkani',
'ably',
'abm',
'abnormal',
'abnormality',
'abodes',
'abolish',
'abolished',
'abolition',
'abolitionism',
'abolitionists',
'abominable',
'abomination',
'abominations',
'abominibal',
'aboreson',
'aborigin',
'aboriginal',
'aborigine',
'aborigines',
'aboriginies',
'aborigins',
'aborigone',
'aborting',
'abortion',
'abortionist',
'abortionists',
'abortions',
'abos',
'abott',
'abounded',
'abounding',
'aboutagirly',
'aboutan',
'abouts',
'abracadabrantesque',
'abrahamic',
'abrasively',
'abrazo',
'abridge',
'abril',
'abromowitz',
'abs',
'absalom',
'abscessed',
'abscond',
'absconded',
'absconding',
'absences',
'absense',
'absentminded',
'absentmindedly',
'abskani',
'absolom',
'absolutelly',
'absoluter',
'absolutey',
'absolutlely',
'absolutley',
'absolve',
'absorbent',
'absorbing',
'absorbs',
'absoutley',
'abstained',
'abstains',
'abstracted',
'abstraction',
'absurd',
'absurder',
'absurdism',
'abt',
'abu',
'abuelita',
'abunch',
'abusers',
'abuses',
'abusively',
'abut',
'abutted',
'abuzz',
'abvious',
'aby',
'abydos',
'abysmal',
'abysmally',
'abyssmal',
'abysymal',
'ac',
'acadamy',
'academe',
'academically',
'acadmey',
'acapella',
'acc',
'accapella',
'acceded',
'accedes',
'accelerant',
'accelerated',
'acceleration',
'accelerator',
'accentuated',
'accentuates',
'accentuation',
'acceptation',
'acceptence',
'acception',
'accesible',
'accessability',
'accessed',
'accessible',
'accession',
'accessorizing',
'accessory',
'accidentee',
'accidently',
'acclamation',
'acclimate',
'acclimation',
'accolade',
'accommodated',
'accommodates',
'accompagnied',
'accomplishes',
'accordian',
'accordion',
'accords',
'accorsi',
'accost',
'accountability',
'accountable',
'accountancy',
'accouterments',
'accredited',
'accrutements',
'acct',
'accumulate',
'accumulates',
'accuracies',
'accursed',
'accusation',
'accusers',
'accustomed',
'acd',
'aced',
'acedemy',
'acedmy',
'acerbic',
'acerbity',
'acetylene',
'achad',
'achala',
'acharya',
'acheaology',
'ached',
'acheived',
'achero',
'achievable',
'achieveing',
'achievement',
'achievements',
'achievers',
'achile',
'achilleas',
'achilles',
'achra',
'achterbusch',
'acidently',
'acidic',
'acidity',
'acids',
'acin',
'acing',
'aciton',
'ack',
'acker',
'ackerman',
'ackland',
'acknowledging',
'acknowledgments',
'aclear',
'aclu',
'acmetropolis',
'acolytes',
'acomplication',
'acorn',
'acorns',
'acoustics',
'acp',
'acquaint',
'acquaintaces',
'acquaints',
'acquart',
'acquiescence',
'acquisition',
'acquitane',
'acquits',
'acrap',
'acrid',
'acrimonious',
'acrimony',
'acronymic',
'acropolis',
'acs',
'actally',
'actelone',
'actess',
'actin',
'actingjob',
'actings',
'actingwise',
'actio',
'actiona',
'actioned',
'actioneer',
'actioneers',
'actionless',
'actionmovie',
'actionpacked',
'actionscenes',
'activate',
'activated',
'actives',
'activest',
'activision',
'activism',
'actores',
'actorsactresses',
'actorsi',
'actorstallone',
'actorsthey',
'actra',
'actreesess',
'actriss',
'actualization',
'actualize',
'actuall',
'actuelly',
'actullly',
'acturly',
'acual',
'acually',
'acumen',
'acupat',
'acurately',
'acus',
'adabted',
'adachi',
'adage',
'adagio',
'adalbert',
'adama',
'adamantium',
'adames',
'adamos',
'adaptable',
'adaptaion',
'adapters',
'adapts',
'adcox',
'addam',
'addario',
'addicting',
'addictions',
'addictive',
'addio',
'addison',
'additive',
'additives',
'addled',
'addons',
'addy',
'adell',
'ademir',
'aden',
'adenoidal',
'adeptness',
'adequateand',
'adgth',
'adhered',
'adherent',
'adheres',
'adhura',
'adibah',
'adien',
'adios',
'aditiya',
'adj',
'adjani',
'adjournment',
'adjunct',
'adjuncts',
'adjurdubois',
'adjust',
'adjusted',
'adjuster',
'adjustin',
'adjustment',
'adjutant',
'adkins',
'adm',
'adma',
'adman',
'admarible',
'administer',
'administered',
'administering',
'administrations',
'adminsitrative',
'admira',
'admirably',
'admirals',
'admiralty',
'admiration',
'admirees',
'admissible',
'admitedly',
'admitt',
'admittadly',
'admittance',
'admittingly',
'admixtures',
'admonish',
'admonishes',
'admonishing',
'admonition',
'adnausem',
'adolphs',
'adone',
'adonis',
'adoptee',
'adoptees',
'adopter',
'adopting',
'adoptive',
'adorable',
'adorably',
'adorble',
'adored',
'adores',
'adorible',
'adorning',
'adotped',
'adr',
'adreno',
'adreon',
'adriano',
'adriatic',
'adrift',
'adroitly',
'ads',
'adt',
'adulating',
'adulhood',
'adulterate',
'adulterated',
'adulteress',
'adulteries',
'adulthood',
'adultism',
'adultry',
'advan',
'advancing',
'advani',
'advantaged',
'advent',
'adventist',
'adventured',
'adventuring',
'adventurously',
'adventurousness',
'adversities',
'adversity',
'advertise',
'advertized',
'advices',
'advisable',
'advisement',
'adviser',
'advisers',
'advision',
'advisory',
'advocated',
'ae',
'aed',
'aegean',
'aeneid',
'aeons',
'aerobic',
'aerobicide',
'aerobics',
'aerodynamic',
'aeronautical',
'aesir',
'aesop',
'aestheically',
'aesthete',
'aesthetical',
'aestheticism',
'aetheist',
'aetherial',
'aetv',
'afb',
'afest',
'afew',
'aff',
'affability',
'affaire',
'affect',
'affectation',
'affectations',
'affectedly',
'affecting',
'affectingly',
'affection',
'affectionate',
'affectionnates',
'affective',
'affectts',
'afficinados',
'afficionado',
'afficionados',
'affinities',
'affirm',
'affirmation',
'affirmations',
'affirmatively',
'affirms',
'affixed',
'affleck',
'afflect',
'afflict',
'afflictions',
'affluent',
'affordable',
'affront',
'affronting',
'affronts',
'affter',
'afgahnistan',
'afgan',
'afgani',
'afghani',
'afghanistan',
'afi',
'afican',
'afield',
'afilm',
'afirming',
'afis',
'afl',
'aflac',
'aflame',
'afm',
'afonya',
'afoot',
'aformentioned',
'afortunately',
'afresh',
'africanism',
'afrika',
'afrikaner',
'afrikanerdom',
'afrikaners',
'afrovideo',
'aft',
'afterbirth',
'afterglow',
'aftermath',
'afternoons',
'afterschool',
'aftershock',
'afterstory',
'aftertaste',
'afterthoughts',
'afterwardsalligator',
'afterwhile',
'afterword',
'afterwords',
'afterworld',
'aftra',
'afv',
'agaaaain',
'agae',
'agbayani',
'agee',
'agekudos',
'ageless',
'agendas',
'agentine',
'ager',
'agers',
'ages',
'agey',
'aggelopoulos',
'aggh',
'aggrandizement',
'aggravate',
'aggravating',
'aggresive',
'aggressed',
'aggrieved',
'aggrivating',
'agha',
'aghhh',
'aghnaistan',
'agi',
'agian',
'agility',
'agis',
'agitator',
'agitators',
'agito',
'aglae',
'agnew',
'agnieszka',
'agniezska',
'agnisakshi',
'agnostic',
'agnosticism',
'agnus',
'agonia',
'agonies',
'agonise',
'agonisingly',
'agonize',
'agonized',
'agonizing',
'agoraphobic',
'agostino',
'agrama',
'agrandizement',
'agrarian',
'agrawal',
'agreeable',
'agreeably',
'agreeing',
'agreements',
'agricultural',
'agro',
'agrument',
'aguila',
'aguilera',
'agust',
'agusti',
'agutter',
'ahab',
'ahah',
'ahahahah',
'ahahahahahaaaaa',
'ahahahahahhahahahahahahahahahhahahahahahahah',
'ahahhahahaha',
'ahamad',
'ahamd',
'ahehehe',
'ahem',
'ahet',
'ahhhhh',
'ahhhhhh',
'ahhhhhhhhh',
'ahista',
'ahistorical',
'ahlan',
'ahlberg',
'ahlstedt',
'ahn',
'ahold',
'aholocolism',
'ahoy',
'aicha',
'aicn',
'aiello',
'aielo',
'aiieeee',
'aiken',
'aikido',
'aikidoist',
'ailed',
'ailes',
'ailing',
'ailment',
'ails',
'ailtan',
'ailton',
'aimanov',
'aiming',
'aimlessly',
'aimlessness',
'aince',
'ainley',
'ainsworth',
'aintry',
'aip',
'airbag',
'airball',
'airbrushed',
'aircraft',
'aircrafts',
'aircrew',
'airdate',
'aire',
'airfield',
'airfix',
'airforce',
'airheaded',
'airheadedness',
'airheads',
'airhostess',
'airial',
'airlessness',
'airlift',
'airliners',
'airlock',
'airman',
'airphone',
'airplay',
'airships',
'airsick',
'airspace',
'airstrip',
'airtime',
'airwolf',
'airwolfs',
'airy',
'aishu',
'aisling',
'aissa',
'aitd',
'aito',
'aja',
'ajax',
'ajeeb',
'aji',
'ajikko',
'ajnabe',
'ajnabi',
'ak',
'akai',
'akane',
'akas',
'akbar',
'akelly',
'akerston',
'akhras',
'akhtar',
'akim',
'akimbo',
'akimoto',
'akira',
'akiva',
'akiyama',
'akmed',
'aknowledge',
'akosua',
'akras',
'akria',
'akroyd',
'akshaya',
'akshays',
'akshey',
'akst',
'akte',
'akuzi',
'akyroyd',
'alabaster',
'alacrity',
'aladdin',
'aladin',
'alamothirteen',
'alanis',
'alannis',
'alanrickmaniac',
'alaric',
'alarik',
'alarmist',
'alarmists',
'alarms',
'alaska',
'alaskey',
'alatri',
'albacore',
'albania',
'albanians',
'albas',
'albatross',
'albeniz',
'alberni',
'alberson',
'albertini',
'albertson',
'albiet',
'albin',
'albino',
'albizo',
'albizu',
'albniz',
'albot',
'albright',
'albums',
'alcaine',
'alcantara',
'alcatraz',
'alchemical',
'alchemist',
'alchemize',
'alchoholic',
'alcoholically',
'alcott',
'alcs',
'alda',
'aldar',
'alderich',
'alderson',
'aldiss',
'aldofo',
'aldolpho',
'aldridge',
'aldwych',
'alecks',
'alegria',
'aleination',
'aleisa',
'alejo',
'alekos',
'aleksandar',
'aleksei',
'aleopathic',
'ales',
'alesia',
'alessio',
'alexanader',
'alexanderplatz',
'alexanders',
'alexandr',
'alexandre',
'alexej',
'alexio',
'alexondra',
'aleya',
'alfio',
'alfre',
'alfrie',
'alfven',
'algae',
'alger',
'algerian',
'algerians',
'algie',
'algiers',
'algorithm',
'algrant',
'algy',
'alibi',
'alibis',
'alicianne',
'alienate',
'alienates',
'alienator',
'alienness',
'alighting',
'aligned',
'aligning',
'alija',
'alik',
'alikethat',
'alimony',
'alisan',
'aliso',
'alissia',
'alistar',
'alita',
'alittle',
'ality',
'alives',
'alki',
'alladin',
'allahabad',
'allay',
'allayli',
'alldredge',
'alleb',
'alledgedly',
'allegation',
'allegations',
'alleged',
'allegiances',
'alleging',
'allegorical',
'allegorically',
'allens',
'allergic',
'allergies',
'alleyways',
'allgret',
'alliance',
'alliende',
'alligator',
'alllll',
'allllllll',
'allmighty',
'allnut',
'allocation',
'alloimono',
'allot',
'alloted',
'allotting',
'allover',
'allowance',
'allowances',
'allright',
'allsuperb',
'allthe',
'allthewhile',
'allthis',
'allthrop',
'alludes',
'allurement',
'allures',
'allusive',
'allwyn',
'almanesque',
'almeida',
'almerayeda',
'almereyda',
'almodvar',
'almonds',
'almora',
'almoust',
'alock',
'aloft',
'aloha',
'alohalani',
'alois',
'alok',
'aloknath',
'alon',
'alona',
'alones',
'alongs',
'aloo',
'alos',
'alosio',
'alothugh',
'alotta',
'aloung',
'alp',
'alpahabet',
'alpert',
'alphabetti',
'alphas',
'alpine',
'alredy',
'alright',
'alrite',
'alsanjak',
'alselmo',
'alsobrook',
'alsoduring',
'altair',
'altaira',
'altaire',
'altamont',
'alterated',
'altercations',
'alterego',
'alterio',
'alterior',
'alternante',
'alternating',
'alternation',
'alternations',
'alternativa',
'althogh',
'althou',
'altieri',
'altioklar',
'altitude',
'altmanesque',
'alto',
'altough',
'altro',
'altron',
'altruism',
'altruistically',
'alucard',
'alucarda',
'alum',
'aluminium',
'aluminum',
'alumna',
'alumnus',
'alums',
'alun',
'alvaro',
'alveraze',
'alway',
'alwina',
'aly',
'alyn',
'alysons',
'amagula',
'amair',
'amalgam',
'amalgamated',
'amalgamation',
'amalio',
'amalric',
'amamore',
'amamoto',
'aman',
'amandola',
'amang',
'amanhecer',
'amani',
'amann',
'amants',
'amar',
'amassed',
...]
# Extract Features
# The Count Object
oCntVec = CountVectorizer(strip_accents = 'ascii', vocabulary = lDicWord)
mXTrain = oCntVec.fit_transform(lReviewTrain) #<! Fit & Transform
mXTest = oCntVec.fit_transform(lReviewTest) #<! Fit & Transform
# Train Test Split
print(f'The training features data shape: {mXTrain.shape}')
print(f'The training labels data shape: {vYTrain.shape}')
print(f'The test features data shape: {mXTest.shape}')
print(f'The test labels data shape: {vYTest.shape}')
print(f'The unique values of the labels: {np.unique(vY)}')
The training features data shape: (22500, 42550)
The training labels data shape: (22500,)
The test features data shape: (2500, 42550)
The test labels data shape: (2500,)
The unique values of the labels: [0 1]
Classifier Model#
There are 2 common Naive Bayes Models:
Gaussian Naive Bayes
Models each independent feature by \(P \left( {x}_{i} \mid y \right) = \frac{1}{\sqrt{2 \pi {\sigma}_{y}^{2}}} \exp \left( -\frac{{\left( {x}_{i} - {\mu}_{y} \right)}^{2}}{2 {\sigma}_{y}^{2}}\right)\).
The features are assumed to be continuous.
It is the go to choice for the case of continuous variables.
It has some limitation for the case of bounded continuous variables.
Implemented byGaussianNB.Bernoulli Naive Bayes
Models each independent feature by \(P \left( {x}_{i} \mid y \right) = P \left( {x}_{i} \mid y \right) {x}_{i} + \left( 1 - P \left( {x}_{i} \mid y \right) \right) \left( 1 - {x}_{i} \right)\).
Models the probability of the occurrence of the feature per class.
Assumes each feature is binary. It explicitly punishes for non occurrence.
Implemented byBernoulliNB.Multinomial Naive Bayes
Models each independent feature by \(P \left( {x}_{1}, {x}_{2}, \dots, {x}_{d} \mid y \right) = \frac{d!}{{x}_{1}! {x}_{2}! \cdots {x}_{d}!} {p}_{1}^{{x}_{1}} {p}_{2}^{{x}_{2}} \cdots {p}_{d}^{{x}_{d}}\).
Models the counting of the feature per class.
Assumes each feature is non negative integer.
Implemented byMultinomialNB.
(#) In lectures, the Gaussian Model does not assume independence of the features as above.
(#) Though the Multinomial Naive Bayes assume counts, in the context of text features, it is known to work well with Term Frequency - Inverse Document Frequency (TF-IDF) features as well.
See How to Use TFIDF Vectors with Multinomial Naive Bayes.(#) The Multinomial Naive Bayes sets the probability according to the counts, the more the better. The Bernoulli Naive Bayes sets the probability based on occurrence, it punishes if there is no occurrence. Hence Bernoulli Naive Bayes has the benefit of explicitly modelling the absence of terms. It implies that a Multinomial Naive Bayes classifier with frequency counts truncated to one is not equivalent of Bernoulli Naive Bayes classifier. See Difference Between Bernoulli and Multinomial Naive Bayes.
In the case above, to match the counts the Multinomial Naive Bayes classifier will be used.
(#) Some advantages of NB Classifiers:
Easy to train and predict with decent results in many cases.
Usually, have a closed form solution for their parameters.
Can handle new data efficiently (See the
partial_fitmethod).Can handle mixed type of features inherently.
(#) Some disadvantages of NB Classifiers:
Can not be extended by Ensembling, Boosting, Bagging as there is no variance to reduce.
Multinomial model assumes the counts will be similar in train and test sets (Otherwise, requires smoothing).
Performance degrades as the features becomes more dependent.
Highly sensitive to imbalanced data.
(?) How mixed features, continuous, counts and binary, can be handled?
— multiply the separated probabilities of the same type aggragate;
# NB Classfier Model
oMultNomNBcls = MultinomialNB(alpha = α)
oMultNomNBcls = oMultNomNBcls.fit(mXTrain, vYTrain)
# Performance Train Data
vHatY = oMultNomNBcls.predict(mXTrain)
vYGt = vYTrain
valAcc = np.mean(vHatY == vYGt)
valPrecision, valRecall, valF1, _ = precision_recall_fscore_support(vYGt, vHatY, pos_label = 1, average = 'binary')
print(f'Accuracy = {valAcc:0.3f}')
print(f'Precision = {valPrecision:0.3f}')
print(f'Recall = {valRecall:0.3f}' )
print(f'F1 Score = {valF1:0.3f}' )
dScore = {'Accuracy': valAcc}
hF, hA = plt.subplots(figsize = (8, 8))
PlotConfusionMatrix(vYGt, vHatY, normMethod = 'true', hA = hA, dScore = dScore, valFormat = '0.1%') #<! The accuracy should be >= than above!
plt.show()
# Performance Test Data
vHatY = oMultNomNBcls.predict(mXTest)
vYGt = vYTest
valAcc = np.mean(vHatY == vYGt)
valPrecision, valRecall, valF1, _ = precision_recall_fscore_support(vYGt, vHatY, pos_label = 1, average = 'binary')
print(f'Accuracy = {valAcc:0.3f}')
print(f'Precision = {valPrecision:0.3f}')
print(f'Recall = {valRecall:0.3f}' )
print(f'F1 Score = {valF1:0.3f}' )
dScore = {'Accuracy': valAcc}
hF, hA = plt.subplots(figsize = (8, 8))
PlotConfusionMatrix(vYGt, vHatY, normMethod = 'true', hA = hA, dScore = dScore, valFormat = '0.1%') #<! The accuracy should be >= than above!
plt.show()
(@) Redo the exercise using TF-IDF. See SciKit Learn’s
TfidfTransformerandTfidfVectorizer.(@) Redo the exercise using Bernoulli Naive Bayes classifier. Adjust the features accordingly.
(@) Try to improve results for accuracy. You may use
NLTKLemmatizer (WordNetLemmatizer).(#) You may read about The Difference Between a Bayesian Network and a Naive Bayes Classifier.
It has a great example on the XOR Problem and the problem with the assumption of feature independence.(#) You may read about The Difference Between a Bayesian Network and a Naive Bayes Classifier (Different source).
(#) You may read about Bayesian Neural Networks: Implementing, Training, Inference With the JAX Framework.
(#) To work with mixed features:
Build a Multinomial NB classifier for the count based features.
Build a Bernoulli NB classifier using the binary features.
Build a Gaussian NB classifier using the continuous features.
Multiply the probabilities of each model to find the maximum probability based on all features (Using the **independence assumption).
(#) Categorical features can be transformed into counts using dummy variables.
(#) Some continuous features should be engineered to better suit a Gaussian model (Like
log()).