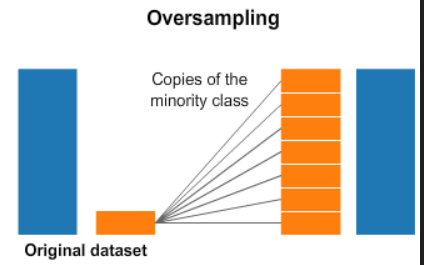
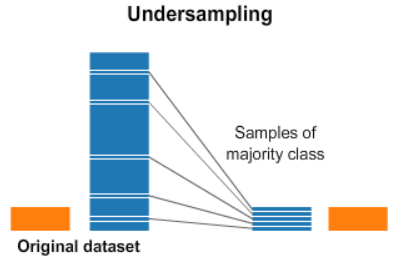
resampling#
There is a dedicated Python package for that called
imbalanced-learnin practice resampling only on the training data set - This is in order to avoid data leakage.
undersampling#
# mX is the feature matrix
# vY is the target vector
len_feat_1 = mX0.shape[0] ## assume large ; for example 1000
len_feat_0 = mX1.shape[0] ## assume small ; for example 50
## create a random index from 1-1000 with 50 samples
vIdx0UnderSample = np.random.choice(len_feat_1, len_feat_0, replace = False)
## filter by index to get the undersampled feature matrix in size of 50
mX0UnderSample = mX0[vIdx0UnderSample]
## create the new feature matrix with both classes in len 50 ; use the small one as is
mXS = np.vstack((mX0UnderSample, mX1))
## build the label vector accordingly
vYS = np.concatenate((np.zeros(mX0UnderSample.shape[0], dtype = vY.dtype), np.ones(mX1.shape[0], dtype = vY.dtype)))
oversampling#