
Image Classification Fashion MNIST#
Notebook by:
Royi Avital RoyiAvital@fixelalgorithms.com
Revision History#
Version |
Date |
User |
Content / Changes |
|---|---|---|---|
1.0.000 |
27/04/2024 |
Royi Avital |
First version |
![]()
# Import Packages
# General Tools
import numpy as np
import scipy as sp
import pandas as pd
# Machine Learning
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
# Deep Learning
import torch
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
import torchinfo
from torchmetrics.classification import MulticlassAccuracy
import torchvision
# Miscellaneous
import math
import os
from platform import python_version
import random
import time
# Typing
from typing import Callable, Dict, Generator, List, Optional, Self, Set, Tuple, Union
# Visualization
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
# Jupyter
from IPython import get_ipython
from IPython.display import HTML, Image
from IPython.display import display
from ipywidgets import Dropdown, FloatSlider, interact, IntSlider, Layout, SelectionSlider
from ipywidgets import interact
2024-06-05 01:57:06.954775: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: SSE4.1 SSE4.2 AVX AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
Notations#
(?) Question to answer interactively.
(!) Simple task to add code for the notebook.
(@) Optional / Extra self practice.
(#) Note / Useful resource / Food for thought.
Code Notations:
someVar = 2; #<! Notation for a variable
vVector = np.random.rand(4) #<! Notation for 1D array
mMatrix = np.random.rand(4, 3) #<! Notation for 2D array
tTensor = np.random.rand(4, 3, 2, 3) #<! Notation for nD array (Tensor)
tuTuple = (1, 2, 3) #<! Notation for a tuple
lList = [1, 2, 3] #<! Notation for a list
dDict = {1: 3, 2: 2, 3: 1} #<! Notation for a dictionary
oObj = MyClass() #<! Notation for an object
dfData = pd.DataFrame() #<! Notation for a data frame
dsData = pd.Series() #<! Notation for a series
hObj = plt.Axes() #<! Notation for an object / handler / function handler
Code Exercise#
Single line fill
vallToFill = ???
Multi Line to Fill (At least one)
# You need to start writing
????
Section to Fill
#===========================Fill This===========================#
# 1. Explanation about what to do.
# !! Remarks to follow / take under consideration.
mX = ???
???
#===============================================================#
# Configuration
# %matplotlib inline
seedNum = 512
np.random.seed(seedNum)
random.seed(seedNum)
# Matplotlib default color palette
lMatPltLibclr = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf']
# sns.set_theme() #>! Apply SeaBorn theme
runInGoogleColab = 'google.colab' in str(get_ipython())
# Improve performance by benchmarking
torch.backends.cudnn.benchmark = True
# Reproducibility
# torch.manual_seed(seedNum)
# torch.backends.cudnn.deterministic = True
# torch.backends.cudnn.benchmark = False
# Constants
FIG_SIZE_DEF = (8, 8)
ELM_SIZE_DEF = 50
CLASS_COLOR = ('b', 'r')
EDGE_COLOR = 'k'
MARKER_SIZE_DEF = 10
LINE_WIDTH_DEF = 2
D_CLASSES_FASHION_MNIST = {0: 'T-Shirt', 1: 'Trouser', 2: 'Pullover', 3: 'Dress', 4: 'Coat', 5: 'Sandal', 6: 'Shirt', 7: 'Sneaker', 8: 'Bag', 9: 'Boots'}
L_CLASSES_FASHION_MNIST = ['T-Shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Boots']
T_IMG_SIZE_MNIST = (28, 28)
DATA_FOLDER_PATH = 'Data'
TENSOR_BOARD_BASE = 'TB'
# Download Auxiliary Modules for Google Colab
if runInGoogleColab:
!wget https://raw.githubusercontent.com/FixelAlgorithmsTeam/FixelCourses/master/AIProgram/2024_02/DataManipulation.py
!wget https://raw.githubusercontent.com/FixelAlgorithmsTeam/FixelCourses/master/AIProgram/2024_02/DataVisualization.py
!wget https://raw.githubusercontent.com/FixelAlgorithmsTeam/FixelCourses/master/AIProgram/2024_02/DeepLearningPyTorch.py
# Courses Packages
import sys
sys.path.append('/home/vlad/utils')
from DataVisualization import PlotLabelsHistogram, PlotMnistImages
from DeepLearningPyTorch import TrainModel
# General Auxiliary Functions
Fashion MNIST Classification with 2D Convolution Net#
This notebook shows the use of Conv2d layer.
The 2D Convolution layer means there are 2 degrees of freedom for the kernel movement.
This notebook applies image classification (Single label per image) on the Fashion MNIST Data Set.
The notebook presents:
Building a 2D convolution based model which fits Computer Vision tasks.
Use of
torch.nn.Conv2d.Use of
torch.nn.BatchNorm2d.Evaluating several models using TensorBoard.
# Parameters
# Data
numSamplesTrain = 60_000
numSamplesTest = 10_000
# Model
dropP = 0.2 #<! Dropout Layer
# Training
batchSize = 256
numWork = 2 #<! Number of workers
nEpochs = 30
# Visualization
numImg = 3
Generate / Load Data#
Load the Fashion MNIST Data Set.
The Fashion MNIST Data Set is considerably more challenging than the original MNIST though it is still no match to Deep Learning models.
(#) The data set is available at OpenML - Fashion MNIST.
Yet it is not separated into the original test and train sets.
# Load Data
mX, vY = fetch_openml('Fashion-MNIST', version = 1, return_X_y = True, as_frame = False, parser = 'auto')
vY = vY.astype(np.int_) #<! The labels are strings, convert to integer
print(f'The features data shape: {mX.shape}')
print(f'The labels data shape: {vY.shape}')
print(f'The unique values of the labels: {np.unique(vY)}')
The features data shape: (70000, 784)
The labels data shape: (70000,)
The unique values of the labels: [0 1 2 3 4 5 6 7 8 9]
(#) The images are grayscale with size
28x28.
# Pre Process Data
mX = mX / 255.0
(?) Does the scaling affects the standardization (Zero mean, Unit variance) process?
Plot the Data#
# Plot the Data
hF = PlotMnistImages(mX, vY, numImg)
plt.show()

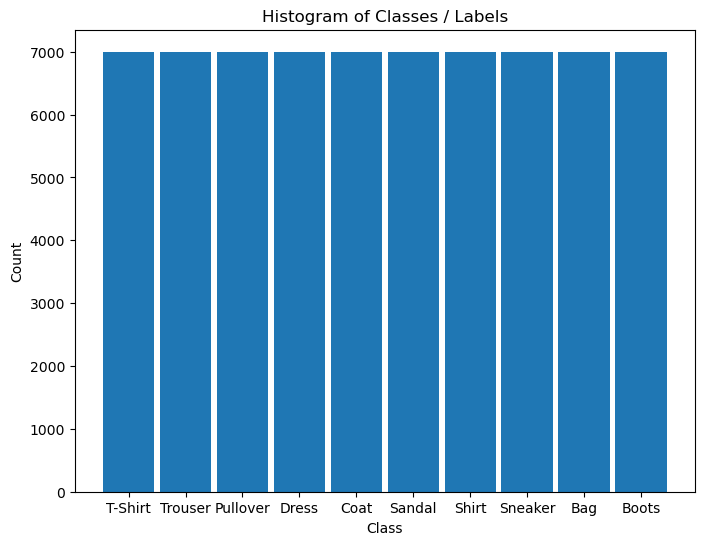
# Histogram of Labels
hA = PlotLabelsHistogram(vY, lClass = L_CLASSES_FASHION_MNIST)
plt.show()
Train & Test Split#
# Train Test Split
numClass = len(np.unique(vY))
#===========================Fill This===========================#
# 1. Split the data into train and test (Validation) data sets (NumPy arrays).
# 2. Use stratified split.
# !! The output should be: `mXTrain`, `mXTest`, `vYTrain`, `vYTest`.
mXTrain, mXTest, vYTrain, vYTest = train_test_split(mX, vY, test_size = numSamplesTest, train_size = numSamplesTrain, shuffle = True, stratify = vY)
#===============================================================#
print(f'The training features data shape: {mXTrain.shape}')
print(f'The training labels data shape: {vYTrain.shape}')
print(f'The test features data shape: {mXTest.shape}')
print(f'The test labels data shape: {vYTest.shape}')
print(f'The unique values of the labels: {np.unique(vY)}')
The training features data shape: (60000, 784)
The training labels data shape: (60000,)
The test features data shape: (10000, 784)
The test labels data shape: (10000,)
The unique values of the labels: [0 1 2 3 4 5 6 7 8 9]
# Torch Datasets
#===========================Fill This===========================#
# 1. Convert the arrays to the 2D shape as needed.
# 2. Generate Torch data sets from the NumPy arrays.
# !! The output should be: `dsTrain`, `dsTest`.
# !! Verify the number of channels is well defined.
# !! The `T_IMG_SIZE_MNIST` tuple might be useful.
# !! The `torch.utils.data.TensorDataset` class might be useful.
# !! Pay attention to the type of the data as tensors.
dsTrain = torch.utils.data.TensorDataset(torch.tensor(np.reshape(mXTrain, (numSamplesTrain, 1, *T_IMG_SIZE_MNIST)), dtype = torch.float32), torch.tensor(vYTrain, dtype = torch.long))
dsTest = torch.utils.data.TensorDataset(torch.tensor(np.reshape(mXTest, (numSamplesTest, 1, *T_IMG_SIZE_MNIST)), dtype = torch.float32), torch.tensor(vYTest, dtype = torch.long))
#===============================================================#
print(f'The training data set data shape: {(len(dsTrain), *dsTrain.tensors[0].shape[1:])}')
print(f'The test data set data shape: {(len(dsTest), *dsTrain.tensors[0].shape[1:])}')
The training data set data shape: (60000, 1, 28, 28)
The test data set data shape: (10000, 1, 28, 28)
Pre Process Data#
This section normalizes the data to have zero mean and unit variance per channel.
It is required to calculate:
The average pixel value per channel.
The standard deviation per channel.
# Calculate the Standardization Parameters
#===========================Fill This===========================#
# 1. Calculate the mean per channel.
# 2. Calculate the standard deviation per channel.
µ = torch.mean(dsTrain.tensors[0])
σ = torch.std(dsTrain.tensors[0])
#===============================================================#
print('µ =', µ)
print('σ =', σ)
µ = tensor(0.2861)
σ = tensor(0.3529)
# Update Transformer
#===========================Fill This===========================#
# 1. Define a transformer which normalizes the data.
# 2. Update the `transform` object in `dsTrain` and `dsTest`.
oDataTrns = torchvision.transforms.Compose([ #<! Chaining transformations
torchvision.transforms.ToTensor(), #<! Convert to Tensor (C x H x W), Normalizes into [0, 1] (https://pytorch.org/vision/main/generated/torchvision.transforms.ToTensor.html)
torchvision.transforms.Normalize(µ, σ), #<! Normalizes the Data (https://pytorch.org/vision/main/generated/torchvision.transforms.Normalize.html)
])
# Update the DS transformer
dsTrain.transform = oDataTrns
dsTest.transform = oDataTrns
#===============================================================#
# "Normalized" Image
mX, valY = dsTrain[5]
hF, hA = plt.subplots()
hA.imshow(np.transpose(mX, (1, 2, 0)))
plt.show()
Data Loaders#
The dataloader is the functionality which loads the data into memory in batches.
Its challenge is to bring data fast enough so the Hard Disk is not the training bottleneck.
In order to achieve that, Multi Threading / Multi Process is used.
# Data Loader
#===========================Fill This===========================#
# 1. Create the train data loader.
# 2. Create the test data loader.
# !! Think about the values of `shuffle` and `batch_size` for the train / test.
dlTrain = torch.utils.data.DataLoader(dsTrain, shuffle = True, batch_size = 1 * batchSize, num_workers = numWork, persistent_workers = True)
dlTest = torch.utils.data.DataLoader(dsTest, shuffle = False, batch_size = 2 * batchSize, num_workers = numWork, persistent_workers = True)
#===============================================================#
# Iterate on the Loader
# The first batch.
tX, vY = next(iter(dlTrain)) #<! PyTorch Tensors
print(f'The batch features dimensions: {tX.shape}')
print(f'The batch labels dimensions: {vY.shape}')
The batch features dimensions: torch.Size([256, 1, 28, 28])
The batch labels dimensions: torch.Size([256])
Define the Model#
This section build 3 different models to be evaluated.
# Model Container
lModels = []
# Model 1
# Defining a sequential model.
oModel = nn.Sequential(
#===========================Fill This===========================#
# 1. Create the 1st model.
# 2. Use 3 layers.
# !! You may use different kernel size, dropout probability, max pooling, etc...
nn.Identity(),
nn.Conv2d(in_channels = 1, out_channels = 30, kernel_size = 3, bias = False),
nn.BatchNorm2d(num_features = 30),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.Conv2d(in_channels = 30, out_channels = 60, kernel_size = 3, bias = False),
nn.MaxPool2d(kernel_size = 2),
nn.BatchNorm2d(num_features = 60),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.Conv2d(in_channels = 60, out_channels = 120, kernel_size = 3, bias = False),
nn.MaxPool2d(kernel_size = 2),
nn.BatchNorm2d(num_features = 120),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(120, len(L_CLASSES_FASHION_MNIST)),
#===============================================================#
)
info = torchinfo.summary(oModel, tX.shape, col_names = ['kernel_size', 'output_size', 'num_params'], device = 'cpu') #<! Added `kernel_size`
print(info)
layers1 = []
for layer in info.summary_list:
layers1.append((layer.class_name, layer.num_params))
# Append Model
lModels.append(oModel)
===================================================================================================================
Layer (type:depth-idx) Kernel Shape Output Shape Param #
===================================================================================================================
Sequential -- [256, 10] --
├─Identity: 1-1 -- [256, 1, 28, 28] --
├─Conv2d: 1-2 [3, 3] [256, 30, 26, 26] 270
├─BatchNorm2d: 1-3 -- [256, 30, 26, 26] 60
├─ReLU: 1-4 -- [256, 30, 26, 26] --
├─Dropout2d: 1-5 -- [256, 30, 26, 26] --
├─Conv2d: 1-6 [3, 3] [256, 60, 24, 24] 16,200
├─MaxPool2d: 1-7 2 [256, 60, 12, 12] --
├─BatchNorm2d: 1-8 -- [256, 60, 12, 12] 120
├─ReLU: 1-9 -- [256, 60, 12, 12] --
├─Dropout2d: 1-10 -- [256, 60, 12, 12] --
├─Conv2d: 1-11 [3, 3] [256, 120, 10, 10] 64,800
├─MaxPool2d: 1-12 2 [256, 120, 5, 5] --
├─BatchNorm2d: 1-13 -- [256, 120, 5, 5] 240
├─ReLU: 1-14 -- [256, 120, 5, 5] --
├─Dropout2d: 1-15 -- [256, 120, 5, 5] --
├─AdaptiveAvgPool2d: 1-16 -- [256, 120, 1, 1] --
├─Flatten: 1-17 -- [256, 120] --
├─Linear: 1-18 -- [256, 10] 1,210
===================================================================================================================
Total params: 82,900
Trainable params: 82,900
Non-trainable params: 0
Total mult-adds (Units.GIGABYTES): 4.09
===================================================================================================================
Input size (MB): 0.80
Forward/backward pass size (MB): 202.28
Params size (MB): 0.33
Estimated Total Size (MB): 203.42
===================================================================================================================
# Model 2
# Defining a sequential model.
oModel = nn.Sequential(
#===========================Fill This===========================#
# 1. Create the 2nd model.
# 2. Use 3 layers.
# !! You may use different kernel size, dropout probability, max pooling, etc...
nn.Identity(),
nn.Conv2d(in_channels = 1, out_channels = 30, kernel_size = 5, bias = False),
nn.BatchNorm2d(num_features = 30),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.Conv2d(in_channels = 30, out_channels = 60, kernel_size = 5, bias = False),
nn.BatchNorm2d(num_features = 60),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.Conv2d(in_channels = 60, out_channels = 120, kernel_size = 5, bias = False),
nn.BatchNorm2d(num_features = 120),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(120, len(L_CLASSES_FASHION_MNIST)),
#===============================================================#
)
info = torchinfo.summary(oModel, tX.shape, col_names = ['kernel_size', 'output_size', 'num_params'], device = 'cpu') #<! Added `kernel_size`
print(info)
layers2 = []
for layer in info.summary_list:
layers2.append((layer.class_name, layer.num_params))
# Append Model
lModels.append(oModel)
===================================================================================================================
Layer (type:depth-idx) Kernel Shape Output Shape Param #
===================================================================================================================
Sequential -- [256, 10] --
├─Identity: 1-1 -- [256, 1, 28, 28] --
├─Conv2d: 1-2 [5, 5] [256, 30, 24, 24] 750
├─BatchNorm2d: 1-3 -- [256, 30, 24, 24] 60
├─ReLU: 1-4 -- [256, 30, 24, 24] --
├─Dropout2d: 1-5 -- [256, 30, 24, 24] --
├─Conv2d: 1-6 [5, 5] [256, 60, 20, 20] 45,000
├─BatchNorm2d: 1-7 -- [256, 60, 20, 20] 120
├─ReLU: 1-8 -- [256, 60, 20, 20] --
├─Dropout2d: 1-9 -- [256, 60, 20, 20] --
├─Conv2d: 1-10 [5, 5] [256, 120, 16, 16] 180,000
├─BatchNorm2d: 1-11 -- [256, 120, 16, 16] 240
├─ReLU: 1-12 -- [256, 120, 16, 16] --
├─Dropout2d: 1-13 -- [256, 120, 16, 16] --
├─AdaptiveAvgPool2d: 1-14 -- [256, 120, 1, 1] --
├─Flatten: 1-15 -- [256, 120] --
├─Linear: 1-16 -- [256, 10] 1,210
===================================================================================================================
Total params: 227,380
Trainable params: 227,380
Non-trainable params: 0
Total mult-adds (Units.GIGABYTES): 16.52
===================================================================================================================
Input size (MB): 0.80
Forward/backward pass size (MB): 294.93
Params size (MB): 0.91
Estimated Total Size (MB): 296.64
===================================================================================================================
# Model 3
# Defining a sequential model.
oModel = nn.Sequential(
#===========================Fill This===========================#
# 1. Create the 3rd model.
# 2. Use 3 layers.
# !! You may use different kernel size, dropout probability, max pooling, etc...
nn.Identity(),
nn.Conv2d(in_channels = 1, out_channels = 30, kernel_size = 7, bias = False),
nn.MaxPool2d(kernel_size = 2),
nn.BatchNorm2d(num_features = 30),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.Conv2d(in_channels = 30, out_channels = 60, kernel_size = 5, bias = False),
nn.MaxPool2d(kernel_size = 2),
nn.BatchNorm2d(num_features = 60),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.Conv2d(in_channels = 60, out_channels = 120, kernel_size = 3, bias = False),
nn.BatchNorm2d(num_features = 120),
nn.ReLU(),
nn.Dropout2d(p = dropP),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(120, len(L_CLASSES_FASHION_MNIST)),
#===============================================================#
)
info = torchinfo.summary(oModel, tX.shape, col_names = ['kernel_size', 'output_size', 'num_params'], device = 'cpu') #<! Added `kernel_size`
print(info)
layers3 = []
for layer in info.summary_list:
layers3.append((layer.class_name, layer.num_params))
# Append Model
lModels.append(oModel)
===================================================================================================================
Layer (type:depth-idx) Kernel Shape Output Shape Param #
===================================================================================================================
Sequential -- [256, 10] --
├─Identity: 1-1 -- [256, 1, 28, 28] --
├─Conv2d: 1-2 [7, 7] [256, 30, 22, 22] 1,470
├─MaxPool2d: 1-3 2 [256, 30, 11, 11] --
├─BatchNorm2d: 1-4 -- [256, 30, 11, 11] 60
├─ReLU: 1-5 -- [256, 30, 11, 11] --
├─Dropout2d: 1-6 -- [256, 30, 11, 11] --
├─Conv2d: 1-7 [5, 5] [256, 60, 7, 7] 45,000
├─MaxPool2d: 1-8 2 [256, 60, 3, 3] --
├─BatchNorm2d: 1-9 -- [256, 60, 3, 3] 120
├─ReLU: 1-10 -- [256, 60, 3, 3] --
├─Dropout2d: 1-11 -- [256, 60, 3, 3] --
├─Conv2d: 1-12 [3, 3] [256, 120, 1, 1] 64,800
├─BatchNorm2d: 1-13 -- [256, 120, 1, 1] 240
├─ReLU: 1-14 -- [256, 120, 1, 1] --
├─Dropout2d: 1-15 -- [256, 120, 1, 1] --
├─AdaptiveAvgPool2d: 1-16 -- [256, 120, 1, 1] --
├─Flatten: 1-17 -- [256, 120] --
├─Linear: 1-18 -- [256, 10] 1,210
===================================================================================================================
Total params: 112,900
Trainable params: 112,900
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 763.62
===================================================================================================================
Input size (MB): 0.80
Forward/backward pass size (MB): 44.81
Params size (MB): 0.45
Estimated Total Size (MB): 46.06
===================================================================================================================
summary = pd.DataFrame([layers1, layers2, layers3])
summary.index = ['Model 1', 'Model 2', 'Model 3']
summary
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model 1 | (Sequential, 82900) | (Identity, 0) | (Conv2d, 270) | (BatchNorm2d, 60) | (ReLU, 0) | (Dropout2d, 0) | (Conv2d, 16200) | (MaxPool2d, 0) | (BatchNorm2d, 120) | (ReLU, 0) | (Dropout2d, 0) | (Conv2d, 64800) | (MaxPool2d, 0) | (BatchNorm2d, 240) | (ReLU, 0) | (Dropout2d, 0) | (AdaptiveAvgPool2d, 0) | (Flatten, 0) | (Linear, 1210) |
| Model 2 | (Sequential, 227380) | (Identity, 0) | (Conv2d, 750) | (BatchNorm2d, 60) | (ReLU, 0) | (Dropout2d, 0) | (Conv2d, 45000) | (BatchNorm2d, 120) | (ReLU, 0) | (Dropout2d, 0) | (Conv2d, 180000) | (BatchNorm2d, 240) | (ReLU, 0) | (Dropout2d, 0) | (AdaptiveAvgPool2d, 0) | (Flatten, 0) | (Linear, 1210) | None | None |
| Model 3 | (Sequential, 112900) | (Identity, 0) | (Conv2d, 1470) | (MaxPool2d, 0) | (BatchNorm2d, 60) | (ReLU, 0) | (Dropout2d, 0) | (Conv2d, 45000) | (MaxPool2d, 0) | (BatchNorm2d, 120) | (ReLU, 0) | (Dropout2d, 0) | (Conv2d, 64800) | (BatchNorm2d, 240) | (ReLU, 0) | (Dropout2d, 0) | (AdaptiveAvgPool2d, 0) | (Flatten, 0) | (Linear, 1210) |
(#) Guideline: The smaller the image gets, the deeper it is (More channels).
The intuition, the beginning of the model learns low level features (Small number), deeper learns combinations of features (Larger number).
Training Loop#
Train the Model#
# Check GPU Availability
runDevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') #<! The 1st CUDA device
runDevice
device(type='cuda', index=0)
# Set the Loss & Score
#===========================Fill This===========================#
# 1. Define loss function
# 2. Define score function.
hL = nn.CrossEntropyLoss()
hS = MulticlassAccuracy(num_classes = len(L_CLASSES_FASHION_MNIST), average = 'micro')
hL = hL.to(runDevice) #<! Not required!
hS = hS.to(runDevice)
#===============================================================#
TENSOR_BOARD_BASE
'TB'
run tensor board:
(WorkshopCUDAEnv) ➜ ~ tensorboard --logdir=/home/vlad/tmpLogs/TB --bind_all
# Train the Model
#===========================Fill This===========================#
# 1. Build a loop to evaluate all models.
# 2. Define a TensorBoard Writer per model to keep its score.
# !! You may use `TrainModel()`.
for ii, oModel in enumerate(lModels):
# Hyper Parameter Loop
oTBWriter = SummaryWriter(log_dir = os.path.join('/home/vlad/tmpLogs',TENSOR_BOARD_BASE, f'Model{(ii + 1):03d}'))
oModel = oModel.to(runDevice) #<! Transfer model to device
oOpt = torch.optim.AdamW(oModel.parameters(), lr = 6e-4, betas = (0.9, 0.99), weight_decay = 1e-3) #<! Define optimizer
oRunModel, lTrainLoss, lTrainScore, lValLoss, lValScore , _ = TrainModel(oModel, dlTrain, dlTest, oOpt, nEpochs, hL, hS, oTBWriter = oTBWriter)
oTBWriter.close()
#===============================================================#
Epoch 1 / 30 | Train Loss: 1.202 | Val Loss: 0.755 | Train Score: 0.637 | Val Score: 0.758 | Epoch Time: 8.89 | <-- Checkpoint! |
Epoch 2 / 30 | Train Loss: 0.712 | Val Loss: 0.554 | Train Score: 0.763 | Val Score: 0.816 | Epoch Time: 5.07 | <-- Checkpoint! |
Epoch 3 / 30 | Train Loss: 0.579 | Val Loss: 0.470 | Train Score: 0.801 | Val Score: 0.838 | Epoch Time: 5.05 | <-- Checkpoint! |
Epoch 4 / 30 | Train Loss: 0.507 | Val Loss: 0.407 | Train Score: 0.823 | Val Score: 0.857 | Epoch Time: 5.09 | <-- Checkpoint! |
Epoch 5 / 30 | Train Loss: 0.464 | Val Loss: 0.386 | Train Score: 0.838 | Val Score: 0.864 | Epoch Time: 5.06 | <-- Checkpoint! |
Epoch 6 / 30 | Train Loss: 0.438 | Val Loss: 0.349 | Train Score: 0.846 | Val Score: 0.874 | Epoch Time: 5.06 | <-- Checkpoint! |
Epoch 7 / 30 | Train Loss: 0.416 | Val Loss: 0.339 | Train Score: 0.855 | Val Score: 0.879 | Epoch Time: 5.09 | <-- Checkpoint! |
Epoch 8 / 30 | Train Loss: 0.401 | Val Loss: 0.321 | Train Score: 0.860 | Val Score: 0.884 | Epoch Time: 5.10 | <-- Checkpoint! |
Epoch 9 / 30 | Train Loss: 0.386 | Val Loss: 0.306 | Train Score: 0.864 | Val Score: 0.890 | Epoch Time: 5.08 | <-- Checkpoint! |
Epoch 10 / 30 | Train Loss: 0.377 | Val Loss: 0.304 | Train Score: 0.867 | Val Score: 0.889 | Epoch Time: 5.18 |
Epoch 11 / 30 | Train Loss: 0.367 | Val Loss: 0.294 | Train Score: 0.870 | Val Score: 0.892 | Epoch Time: 5.14 | <-- Checkpoint! |
Epoch 12 / 30 | Train Loss: 0.361 | Val Loss: 0.288 | Train Score: 0.873 | Val Score: 0.895 | Epoch Time: 5.10 | <-- Checkpoint! |
Epoch 13 / 30 | Train Loss: 0.352 | Val Loss: 0.280 | Train Score: 0.875 | Val Score: 0.898 | Epoch Time: 5.12 | <-- Checkpoint! |
Epoch 14 / 30 | Train Loss: 0.345 | Val Loss: 0.279 | Train Score: 0.878 | Val Score: 0.898 | Epoch Time: 5.03 |
Epoch 15 / 30 | Train Loss: 0.338 | Val Loss: 0.270 | Train Score: 0.879 | Val Score: 0.902 | Epoch Time: 5.06 | <-- Checkpoint! |
Epoch 16 / 30 | Train Loss: 0.334 | Val Loss: 0.269 | Train Score: 0.880 | Val Score: 0.902 | Epoch Time: 5.08 |
Epoch 17 / 30 | Train Loss: 0.329 | Val Loss: 0.272 | Train Score: 0.884 | Val Score: 0.904 | Epoch Time: 5.09 | <-- Checkpoint! |
Epoch 18 / 30 | Train Loss: 0.326 | Val Loss: 0.268 | Train Score: 0.885 | Val Score: 0.902 | Epoch Time: 5.07 |
Epoch 19 / 30 | Train Loss: 0.319 | Val Loss: 0.261 | Train Score: 0.888 | Val Score: 0.904 | Epoch Time: 5.11 | <-- Checkpoint! |
Epoch 20 / 30 | Train Loss: 0.320 | Val Loss: 0.254 | Train Score: 0.887 | Val Score: 0.908 | Epoch Time: 5.74 | <-- Checkpoint! |
Epoch 21 / 30 | Train Loss: 0.311 | Val Loss: 0.253 | Train Score: 0.889 | Val Score: 0.909 | Epoch Time: 5.11 | <-- Checkpoint! |
Epoch 22 / 30 | Train Loss: 0.307 | Val Loss: 0.249 | Train Score: 0.891 | Val Score: 0.909 | Epoch Time: 5.09 | <-- Checkpoint! |
Epoch 23 / 30 | Train Loss: 0.308 | Val Loss: 0.248 | Train Score: 0.891 | Val Score: 0.912 | Epoch Time: 5.17 | <-- Checkpoint! |
Epoch 24 / 30 | Train Loss: 0.302 | Val Loss: 0.254 | Train Score: 0.893 | Val Score: 0.909 | Epoch Time: 5.10 |
Epoch 25 / 30 | Train Loss: 0.301 | Val Loss: 0.247 | Train Score: 0.893 | Val Score: 0.911 | Epoch Time: 5.08 |
Epoch 26 / 30 | Train Loss: 0.300 | Val Loss: 0.245 | Train Score: 0.894 | Val Score: 0.912 | Epoch Time: 5.09 | <-- Checkpoint! |
Epoch 27 / 30 | Train Loss: 0.292 | Val Loss: 0.240 | Train Score: 0.897 | Val Score: 0.913 | Epoch Time: 5.09 | <-- Checkpoint! |
Epoch 28 / 30 | Train Loss: 0.292 | Val Loss: 0.242 | Train Score: 0.896 | Val Score: 0.913 | Epoch Time: 5.07 | <-- Checkpoint! |
Epoch 29 / 30 | Train Loss: 0.288 | Val Loss: 0.236 | Train Score: 0.897 | Val Score: 0.915 | Epoch Time: 5.09 | <-- Checkpoint! |
Epoch 30 / 30 | Train Loss: 0.287 | Val Loss: 0.236 | Train Score: 0.899 | Val Score: 0.916 | Epoch Time: 5.10 | <-- Checkpoint! |
Epoch 1 / 30 | Train Loss: 1.082 | Val Loss: 0.677 | Train Score: 0.652 | Val Score: 0.764 | Epoch Time: 11.92 | <-- Checkpoint! |
Epoch 2 / 30 | Train Loss: 0.687 | Val Loss: 0.550 | Train Score: 0.753 | Val Score: 0.800 | Epoch Time: 7.71 | <-- Checkpoint! |
Epoch 3 / 30 | Train Loss: 0.587 | Val Loss: 0.480 | Train Score: 0.787 | Val Score: 0.827 | Epoch Time: 7.75 | <-- Checkpoint! |
Epoch 4 / 30 | Train Loss: 0.533 | Val Loss: 0.438 | Train Score: 0.807 | Val Score: 0.841 | Epoch Time: 7.71 | <-- Checkpoint! |
Epoch 5 / 30 | Train Loss: 0.500 | Val Loss: 0.420 | Train Score: 0.819 | Val Score: 0.846 | Epoch Time: 7.71 | <-- Checkpoint! |
Epoch 6 / 30 | Train Loss: 0.471 | Val Loss: 0.389 | Train Score: 0.831 | Val Score: 0.858 | Epoch Time: 7.67 | <-- Checkpoint! |
Epoch 7 / 30 | Train Loss: 0.449 | Val Loss: 0.376 | Train Score: 0.840 | Val Score: 0.868 | Epoch Time: 7.69 | <-- Checkpoint! |
Epoch 8 / 30 | Train Loss: 0.432 | Val Loss: 0.355 | Train Score: 0.844 | Val Score: 0.871 | Epoch Time: 7.70 | <-- Checkpoint! |
Epoch 9 / 30 | Train Loss: 0.417 | Val Loss: 0.350 | Train Score: 0.850 | Val Score: 0.872 | Epoch Time: 7.72 | <-- Checkpoint! |
Epoch 10 / 30 | Train Loss: 0.407 | Val Loss: 0.335 | Train Score: 0.854 | Val Score: 0.880 | Epoch Time: 7.98 | <-- Checkpoint! |
Epoch 11 / 30 | Train Loss: 0.394 | Val Loss: 0.323 | Train Score: 0.859 | Val Score: 0.882 | Epoch Time: 7.70 | <-- Checkpoint! |
Epoch 12 / 30 | Train Loss: 0.386 | Val Loss: 0.316 | Train Score: 0.861 | Val Score: 0.887 | Epoch Time: 7.74 | <-- Checkpoint! |
Epoch 13 / 30 | Train Loss: 0.376 | Val Loss: 0.311 | Train Score: 0.867 | Val Score: 0.890 | Epoch Time: 7.69 | <-- Checkpoint! |
Epoch 14 / 30 | Train Loss: 0.368 | Val Loss: 0.309 | Train Score: 0.869 | Val Score: 0.892 | Epoch Time: 7.71 | <-- Checkpoint! |
Epoch 15 / 30 | Train Loss: 0.363 | Val Loss: 0.297 | Train Score: 0.870 | Val Score: 0.893 | Epoch Time: 7.67 | <-- Checkpoint! |
Epoch 16 / 30 | Train Loss: 0.356 | Val Loss: 0.294 | Train Score: 0.872 | Val Score: 0.894 | Epoch Time: 7.67 | <-- Checkpoint! |
Epoch 17 / 30 | Train Loss: 0.349 | Val Loss: 0.282 | Train Score: 0.876 | Val Score: 0.898 | Epoch Time: 7.74 | <-- Checkpoint! |
Epoch 18 / 30 | Train Loss: 0.347 | Val Loss: 0.280 | Train Score: 0.877 | Val Score: 0.898 | Epoch Time: 7.73 | <-- Checkpoint! |
Epoch 19 / 30 | Train Loss: 0.342 | Val Loss: 0.280 | Train Score: 0.878 | Val Score: 0.898 | Epoch Time: 7.72 | <-- Checkpoint! |
Epoch 20 / 30 | Train Loss: 0.335 | Val Loss: 0.271 | Train Score: 0.882 | Val Score: 0.900 | Epoch Time: 7.72 | <-- Checkpoint! |
Epoch 21 / 30 | Train Loss: 0.333 | Val Loss: 0.265 | Train Score: 0.881 | Val Score: 0.907 | Epoch Time: 8.09 | <-- Checkpoint! |
Epoch 22 / 30 | Train Loss: 0.329 | Val Loss: 0.261 | Train Score: 0.884 | Val Score: 0.907 | Epoch Time: 7.70 | <-- Checkpoint! |
Epoch 23 / 30 | Train Loss: 0.325 | Val Loss: 0.276 | Train Score: 0.883 | Val Score: 0.900 | Epoch Time: 7.71 |
Epoch 24 / 30 | Train Loss: 0.319 | Val Loss: 0.264 | Train Score: 0.887 | Val Score: 0.906 | Epoch Time: 7.70 |
Epoch 25 / 30 | Train Loss: 0.317 | Val Loss: 0.255 | Train Score: 0.887 | Val Score: 0.907 | Epoch Time: 7.70 |
Epoch 26 / 30 | Train Loss: 0.314 | Val Loss: 0.253 | Train Score: 0.889 | Val Score: 0.906 | Epoch Time: 7.73 |
Epoch 27 / 30 | Train Loss: 0.311 | Val Loss: 0.251 | Train Score: 0.890 | Val Score: 0.908 | Epoch Time: 7.71 | <-- Checkpoint! |
Epoch 28 / 30 | Train Loss: 0.311 | Val Loss: 0.253 | Train Score: 0.889 | Val Score: 0.908 | Epoch Time: 7.71 |
Epoch 29 / 30 | Train Loss: 0.307 | Val Loss: 0.251 | Train Score: 0.891 | Val Score: 0.909 | Epoch Time: 8.00 | <-- Checkpoint! |
Epoch 30 / 30 | Train Loss: 0.301 | Val Loss: 0.249 | Train Score: 0.894 | Val Score: 0.910 | Epoch Time: 7.72 | <-- Checkpoint! |
Epoch 1 / 30 | Train Loss: 0.702 | Val Loss: 0.396 | Train Score: 0.769 | Val Score: 0.859 | Epoch Time: 2.93 | <-- Checkpoint! |
Epoch 2 / 30 | Train Loss: 0.403 | Val Loss: 0.334 | Train Score: 0.856 | Val Score: 0.877 | Epoch Time: 2.43 | <-- Checkpoint! |
Epoch 3 / 30 | Train Loss: 0.355 | Val Loss: 0.302 | Train Score: 0.872 | Val Score: 0.889 | Epoch Time: 2.35 | <-- Checkpoint! |
Epoch 4 / 30 | Train Loss: 0.326 | Val Loss: 0.287 | Train Score: 0.882 | Val Score: 0.894 | Epoch Time: 2.39 | <-- Checkpoint! |
Epoch 5 / 30 | Train Loss: 0.309 | Val Loss: 0.282 | Train Score: 0.887 | Val Score: 0.897 | Epoch Time: 2.42 | <-- Checkpoint! |
Epoch 6 / 30 | Train Loss: 0.297 | Val Loss: 0.275 | Train Score: 0.892 | Val Score: 0.901 | Epoch Time: 2.33 | <-- Checkpoint! |
Epoch 7 / 30 | Train Loss: 0.283 | Val Loss: 0.280 | Train Score: 0.895 | Val Score: 0.896 | Epoch Time: 2.35 |
Epoch 8 / 30 | Train Loss: 0.274 | Val Loss: 0.268 | Train Score: 0.900 | Val Score: 0.899 | Epoch Time: 2.41 |
Epoch 9 / 30 | Train Loss: 0.264 | Val Loss: 0.268 | Train Score: 0.903 | Val Score: 0.901 | Epoch Time: 2.46 |
Epoch 10 / 30 | Train Loss: 0.259 | Val Loss: 0.262 | Train Score: 0.903 | Val Score: 0.906 | Epoch Time: 2.36 | <-- Checkpoint! |
Epoch 11 / 30 | Train Loss: 0.250 | Val Loss: 0.261 | Train Score: 0.908 | Val Score: 0.906 | Epoch Time: 2.36 |
Epoch 12 / 30 | Train Loss: 0.245 | Val Loss: 0.257 | Train Score: 0.909 | Val Score: 0.907 | Epoch Time: 3.11 | <-- Checkpoint! |
Epoch 13 / 30 | Train Loss: 0.237 | Val Loss: 0.261 | Train Score: 0.912 | Val Score: 0.909 | Epoch Time: 2.36 | <-- Checkpoint! |
Epoch 14 / 30 | Train Loss: 0.234 | Val Loss: 0.263 | Train Score: 0.912 | Val Score: 0.906 | Epoch Time: 2.38 |
Epoch 15 / 30 | Train Loss: 0.230 | Val Loss: 0.261 | Train Score: 0.914 | Val Score: 0.905 | Epoch Time: 2.36 |
Epoch 16 / 30 | Train Loss: 0.222 | Val Loss: 0.253 | Train Score: 0.916 | Val Score: 0.908 | Epoch Time: 2.28 |
Epoch 17 / 30 | Train Loss: 0.222 | Val Loss: 0.257 | Train Score: 0.916 | Val Score: 0.906 | Epoch Time: 2.37 |
Epoch 18 / 30 | Train Loss: 0.216 | Val Loss: 0.264 | Train Score: 0.919 | Val Score: 0.905 | Epoch Time: 2.72 |
Epoch 19 / 30 | Train Loss: 0.213 | Val Loss: 0.259 | Train Score: 0.922 | Val Score: 0.908 | Epoch Time: 2.40 |
Epoch 20 / 30 | Train Loss: 0.212 | Val Loss: 0.259 | Train Score: 0.921 | Val Score: 0.910 | Epoch Time: 2.39 | <-- Checkpoint! |
Epoch 21 / 30 | Train Loss: 0.207 | Val Loss: 0.258 | Train Score: 0.923 | Val Score: 0.911 | Epoch Time: 2.41 | <-- Checkpoint! |
Epoch 22 / 30 | Train Loss: 0.204 | Val Loss: 0.261 | Train Score: 0.924 | Val Score: 0.909 | Epoch Time: 2.42 |
Epoch 23 / 30 | Train Loss: 0.201 | Val Loss: 0.265 | Train Score: 0.924 | Val Score: 0.908 | Epoch Time: 2.44 |
Epoch 24 / 30 | Train Loss: 0.199 | Val Loss: 0.259 | Train Score: 0.925 | Val Score: 0.911 | Epoch Time: 2.42 | <-- Checkpoint! |
Epoch 25 / 30 | Train Loss: 0.195 | Val Loss: 0.257 | Train Score: 0.927 | Val Score: 0.912 | Epoch Time: 2.30 | <-- Checkpoint! |
Epoch 26 / 30 | Train Loss: 0.193 | Val Loss: 0.270 | Train Score: 0.927 | Val Score: 0.906 | Epoch Time: 2.38 |
Epoch 27 / 30 | Train Loss: 0.189 | Val Loss: 0.260 | Train Score: 0.930 | Val Score: 0.911 | Epoch Time: 2.37 |
Epoch 28 / 30 | Train Loss: 0.187 | Val Loss: 0.263 | Train Score: 0.929 | Val Score: 0.909 | Epoch Time: 2.40 |
Epoch 29 / 30 | Train Loss: 0.184 | Val Loss: 0.259 | Train Score: 0.930 | Val Score: 0.911 | Epoch Time: 2.71 |
Epoch 30 / 30 | Train Loss: 0.187 | Val Loss: 0.252 | Train Score: 0.930 | Val Score: 0.912 | Epoch Time: 2.58 | <-- Checkpoint! |
(#) Run
tensorboard --logdir=TBfrom the Jupyter notebook path.(@) Optimize the model search to get above 92% accuracy in validation set.
results: validation score#
