Cross Entropy#
Cross entropy is a loss function that is used in classification problems. It is a measure of how well the predicted probabilities of a model match the actual probabilities of the data.
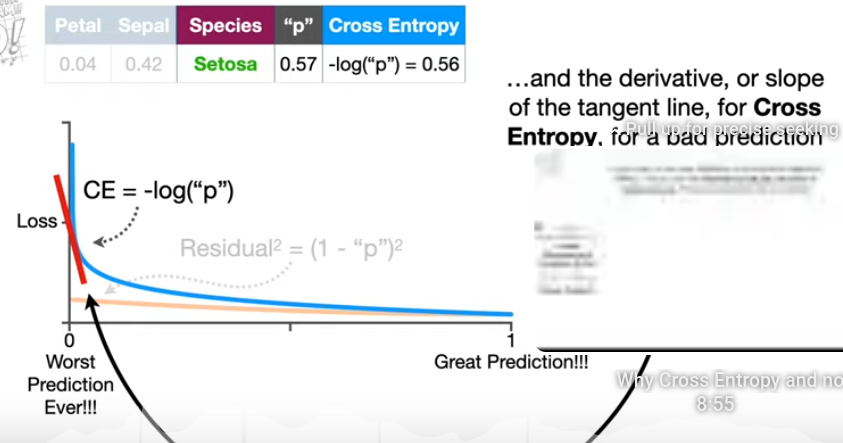
Cross-Entropy#
Overview#
Cross-entropy is a widely used loss function in machine learning, particularly for classification tasks. It measures the difference between two probability distributions: the true distribution (actual labels) and the predicted distribution (model’s output probabilities). By penalizing the differences, cross-entropy guides the optimization process during model training, aiming to improve the accuracy of predictions.
Key Concepts#
Entropy:
Definition: Entropy is a measure of the uncertainty or randomness in a probability distribution. For a distribution \( P \) over a set of events, entropy \( H(P) \) is defined as: $\( H(P) = -\sum_{i} P(i) \log P(i) \)$
Purpose: Provides a baseline for measuring the amount of surprise or information content in an event.
Cross-Entropy:
Definition: Cross-entropy measures the difference between two probability distributions: the true distribution \( P \) and the predicted distribution \( Q \). It is defined as: $\( H(P, Q) = -\sum_{i} P(i) \log Q(i) \)$
Purpose: Quantifies the performance of a classification model by comparing its predicted probabilities with the actual labels. A lower cross-entropy value indicates better model performance.
Binary Cross-Entropy:
Definition: Used for binary classification problems, where the true labels \( y \) are either 0 or 1. The binary cross-entropy loss is given by: $\( L = -\frac{1}{N} \sum_{i=1}^{N} [y_i \log(p_i) + (1 - y_i) \log(1 - p_i)] \)\( where \) y_i \( is the true label and \) p_i $ is the predicted probability.
Purpose: Measures the performance of a binary classifier, penalizing incorrect predictions.
Categorical Cross-Entropy:
Definition: Used for multiclass classification problems, where each instance belongs to one of \( K \) classes. The categorical cross-entropy loss is given by: $\( L = -\frac{1}{N} \sum_{i=1}^{N} \sum_{k=1}^{K} y_{i,k} \log(p_{i,k}) \)\( where \) y_{i,k} \( is a binary indicator (0 or 1) if class label \) k \( is the correct classification for observation \) i \(, and \) p_{i,k} $ is the predicted probability.
Purpose: Measures the performance of a multiclass classifier, encouraging accurate probability distributions for each class.
Applications#
Image Classification: Assessing the performance of models that label images.
Natural Language Processing: Evaluating models for tasks such as sentiment analysis, language translation, and text classification.
Speech Recognition: Measuring the accuracy of models that transcribe spoken words.
Advantages#
Sensitivity to Probability Estimates: Provides a strong penalty for confident but incorrect predictions, encouraging models to improve probability estimates.
Applicability: Suitable for both binary and multiclass classification tasks.
Compatibility: Works well with various optimization algorithms, such as stochastic gradient descent.
Disadvantages#
Computational Complexity: Can be computationally intensive for large datasets or models with many classes.
Numerical Stability: May suffer from numerical instability due to logarithms, particularly when predicted probabilities are close to 0. This can be mitigated by techniques such as adding small values (epsilon) to probabilities before taking the logarithm.
Cross-entropy is a crucial loss function for training classification models, helping to minimize the divergence between predicted and true probability distributions. Understanding its concepts and applications is essential for effectively optimizing and evaluating machine learning models.